
参数调优《GPTune》
当前的调优系统通常利用贝叶斯优化(BO)或强化学习(RL)通过试错来探索空间 。然而,这些方法依然会产生高昂的调优成本,通常需要数百到数千次耗时的迭代才能找到理想配置 。
难点 1:参数太多。现有方法要么选择固定的参数子集,牺牲了灵活性;要么需要极其消耗资源的大量运行来识别重要参数 。
难点 2:搜索空间太大。现有方法大多直接使用 DBMS 供应商提供的默认值域,这些值域过于宽泛,不仅使调优过程复杂化,还引入了系统崩溃的风险。
挑战一(C1):很难在平衡成本与质量的前提下,将异构的自然语言知识统一为机器可读的结构化视图。现有的数据提取和清理工作流复杂且难以满足需求 。
挑战二(C2):即使有了结构化知识,BO 和 RL 等标准优化算法在设计上并不支持直接集成外部领域知识。而单纯人工提取的静态规则又无法适应多变的工作负载环境 。
GPTUNER 的创新设计:
解决 C1:针对 LLM 容易产生幻觉的脆弱特性,设计了一个包含双重纠错机制的 LLM 管道。该管道涵盖数据摄取、基于 LLM 的数据清洗过滤、冲突处理集成以及事实一致性校对。
解决 C2:在调优前利用 LLM 的文本分析能力模拟 DBA 的思维,考虑系统、工作负载和查询瓶颈进行参数降维。在搜索空间上剔除无意义区域并高亮潜力空间 。最后,设计出两种不同粒度的搜索空间,引导贝叶斯优化进行从粗到细(Coarse-to-Fine)的贯穿式探索。
系统架构

知识处理
知识收集
收集不同来源的领域知识,包括官方手册,论坛讨论,由于GPT-4本身就是在大规模网络语料上训练的,所以它本身就是一个操作手册,可以利用LLM作为知识来源。
知识清洗
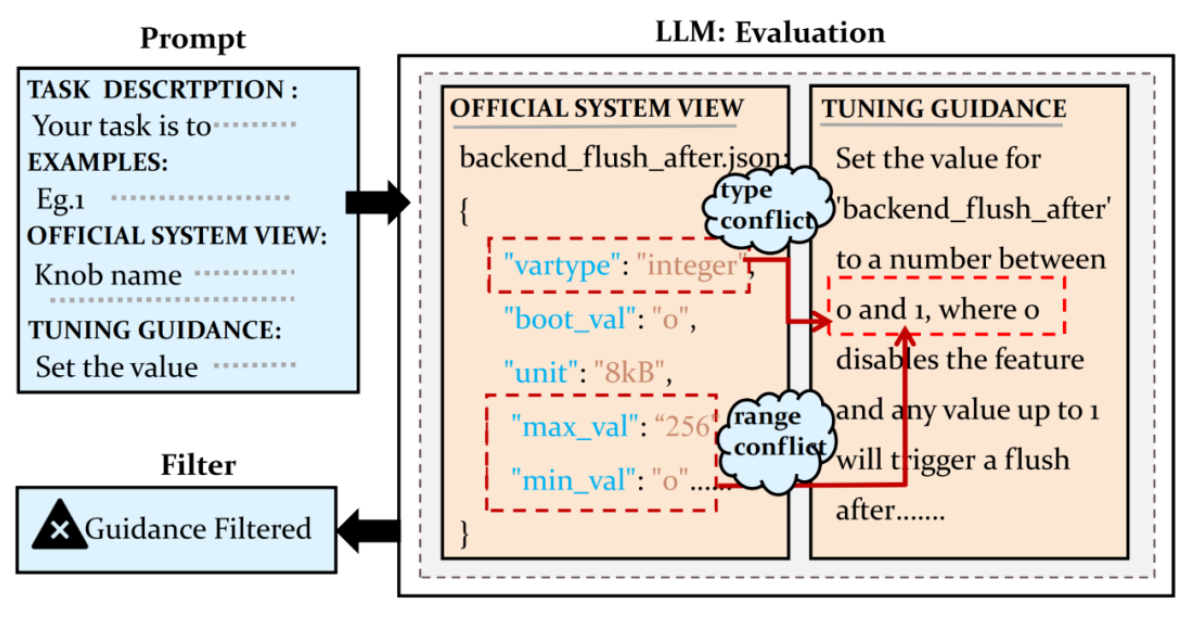
网上收集得到的信息不一定是准确的,甚至可能是相互矛盾的。GPTune 设计了一个基于 LLM 的数据清洗管道,作者通过将此过程建模为“二分类问题”来过滤掉嘈杂知识,并利用 LLM 解决它。作者向 LLM 提供某个参数的候选调优知识以及该参数的官方系统视图(例如,PostgreSQL 中的 pg_settings 和 MySQL 中的 information_schema)。此外,在提示词中给出了一些示例,以利用 LLM 的上下文学习能力。LLM 会评估调优知识是否与系统视图相冲突,并丢弃任何发生冲突的知识。
知识总结
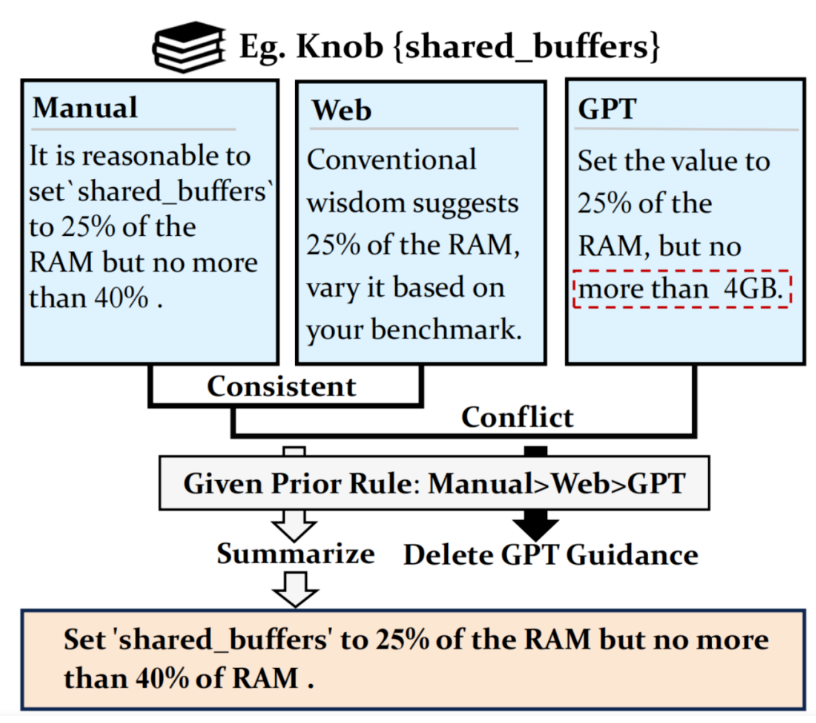
一个参数可能有多种调优知识。虽然此类调优指南服从官方系统视图,但它们可能会相互冲突(例如,不同手册为同一参数提供了不同的推荐值。我们通过基于可靠性手动为每个信息源设置优先级来处理此问题。例如,官方手册具有权威性,因此优先级最高,而由于幻觉问题,LLM 的优先级最低。所以作者总结了不矛盾的指南,并在发生矛盾的部分删除了低优先级的内容。
知识检查
在最后一步中,总结任务由 LLM 完成,生成的总结可能在事实上不一致(即总结包含了未出现在源内容中甚至与其相矛盾的信息)。由于 GPT 作为事实不一致性评估器优于以前的方法,作者利用 GPT 来检查这种不一致性。对于每个参数,提示词中都会包含该总结和源内容,以供 GPT 确定是否存在不一致。如果检测到不一致,系统会提示 GPT 重新生成总结。这个新生成的总结及其源内容会再次提供给 GPT。重复此过程,直到 GPT 识别不出任何错误,从而生成最终总结。
知识转换
构建参数的结构化视图
首先要知道的是,GPTune将知识转化为参数的四个值:
- suggested_values(建议值)
- min_value(最小值)
- max_value(最大值)
- special_value(特殊值)比如0的时候表示关闭这个功能,-1表示不限制等
将转换任务分解为两个子任务:分别提取(1)suggested_values、min_value、max_value 和(2)special_value。单独处理 special_value,因为 special_value 具有其自身的上下文。
大语言模型有一个明显的缺点:你给它的提示词(Prompt)哪怕只微调了几个字,或者换了几个演示用的例子,它输出的格式和结果就可能发生巨大变化,这被称为大模型的“脆弱性”。此外,大模型偶尔还会瞎编数据(幻觉)。如果只让大模型提取一次,一旦格式乱了或者数值提错了,直接喂给后续的数据库调优算法,很容易导致系统崩溃或调优失败。
为了解决这个问题,作者们决定不只让大模型生成一次结果。首先,人类专家手工精心准备了 10 个标准的“提取案例”(例如:输入一段官方手册文字,标准输出的建议值、最大值、最小值各是多少),这就构成了“案例库”(Example Pool,文中设定总数 $K=10$)。
当系统需要从一段新的文本中提取知识时,它会从这 10 个标准案例中,随机抽出 3 个($n=3$)作为示例(少样本学习,few-shots learning),拼接到提示词中去提问。
通过不断重复“随机抽取”这个动作,系统就针对同一段调优文本,构建出了多个略有不同的提示词
把这些不同的提示词分别发给大模型后,大模型会为同一个参数生成多份提取结果(候选的 JSON 数据)。
接下来就是“对答案”的时候了,系统会采用逐元素多数投票策略来从这些候选结果中选出最终的提取结果。
搜索空间优化
维度优化
在 GPTUNER 系统中,搜索空间优化(Search Space Optimization)主要从以下两个核心方面进行:
1. 降维优化 (Dimensionality Optimization)
这一步的核心目的是 挑选出对数据库性能有重大影响的重要参数进行调优,从而减少搜索空间的维度 (即减少需要调优的参数数量),以避免“维度灾难”。GPTUNER 利用大语言模型(LLM)模拟资深数据库管理员(DBA)的经验判断,综合考量以下四个层面的因素来挑选参数:
- 系统级别 (System-Level) :基于特定的数据库管理系统(DBMS)产品,凭借经验选出对该系统极其重要的全局参数。
- 工作负载级别 (Workload-Level) :根据工作负载的类型(如 OLTP 或 OLAP)以及优化目标来选择参数,因为不同工作负载对系统资源的需求截然不同。
- 查询级别 (Query-Level) :让 LLM 深入分析具体耗时查询的“执行计划”,诊断出性能瓶颈,并推荐与该瓶颈相关的参数。
- 参数级别 (Knob-Level) :利用 LLM 的文本分析能力阅读手册,捕获参数之间的依赖关系,将需要联动调整的依赖参数补充到目标参数集中。
2. 值域优化 (Range Optimization)
在选定重要参数后,系统会 针对每个参数的独特语义和相关的调优知识,优化其具体的取值范围 。这主要通过以下三种技术实现:
- 区域剔除 (Region Discard) :利用从知识库中提取的最小值(
min_value)和最大值(max_value),直接剔除掉官方默认值域中那些毫无意义、可能占用过多系统资源或可能导致数据库启动崩溃的危险区域。 - 微小可行空间 (Tiny Feasible Space) :利用提取出的建议值(
suggested_values),通过一套结合参数极值的动态乘数公式,在建议值的周围生成几个按比例偏移的离散候选点。这构成了一个虽然微小但极具产出好结果潜力的离散搜索空间。 - 虚拟参数扩展 (Virtual Knob Extension) :针对那些包含“特殊值”(例如设为 0 代表禁用该功能)的参数,将其拆解并扩展为三个虚拟参数:一个决定是否使用特殊值的 控制开关 (
control_knob)、一个 正常参数 (normal_knob)和一个 特殊参数 (special_knob)。这使得机器学习优化器能够有效地将特殊情况纳入考量范围。
关于微小可行空间的解释:
1.为什么不能直接用建议值,或者简单地翻倍?
假设官方手册建议把参数 checkpoint_timeout 设置为 90。
- 只用建议值:不同硬件环境千差万别,90 只是个起点,直接锁死为 90 可能并不是你当前机器上的最优解。
- 简单翻倍(以前的方法):以前的一些调优工具(比如 DB-BERT)会简单粗暴地给建议值乘上固定的倍数(比如最大乘 4 倍),那就是 $90 \times 4 = 360$。但是,这个参数在数据库里允许的最大极限值其实是 86400!如果最高只试到 360,就白白浪费了后面巨大的探索空间。
2. 结合“参数极值”的动态乘数公式
为了解决上面的问题,GPTUNER 发明了一个公式。这个公式的意思是:“我们以建议值为原点,看看距离最大极限(或最小极限)还有多远,然后切分这段距离,稳步地向极限值迈进。”
在这个公式中(算法数学表达为 $\alpha \cdot V = V + \beta(U-V)$):
- 建议值 ($V$):大本营(比如 90)。
- 参数极值 ($U$):这个参数允许的上限(比如 86400)或下限。
- 比例系数 ($\beta$):论文中设定了几个固定的档位,比如 0(不偏移)、1/4 (0.25) 和 1/2 (0.5)。
3. 具体怎么“按比例偏移生成离散候选点”?
我们就拿刚才的数字算一笔账:
- 距离上限还有多远? $86400 - 90 = 86310$。
- 偏移点 1(原封不动,$\beta=0$):直接保留大本营 90。
- 偏移点 2(向极大值逼近 1/4,$\beta=0.25$):$90 + (86310 \times 0.25) \approx$ 21667。
- 偏移点 3(向极大值逼近 1/2,$\beta=0.5$):$90 + (86310 \times 0.5) \approx$ 43245。
同理,系统也会向着最小值的方向做类似的偏移计算。
从粗到细粒度的贝叶斯优化
在 GPTUNER 系统中,“从粗到细的贝叶斯优化框架”(Coarse-to-Fine Bayesian Optimization Framework)是其寻找最佳数据库参数配置的核心搜索策略。
传统贝叶斯优化在面对数据库几百个参数构成的极其庞大且异构的搜索空间时,通常需要几百上千次高成本的试错迭代才能收敛。为了解决这个痛点,GPTUNER 设计了这个两阶段框架,其核心设计思想是:巧妙结合“粗粒度搜索的高效性”与“细粒度搜索的彻底性”。
具体来说,这个框架分为以下两个阶段:
1. 粗粒度阶段 (Coarse-grained Stage):高效锁定“潜力股”
这个阶段的目的是以极低的试错成本,快速获得一个虽然非全局最优、但已经非常优秀的基准配置。
- 限定微小空间:系统首先不会在整个广阔的参数空间里盲目搜索,而是将目光锁定在先前通过领域知识(如官方手册中的建议值)生成的**“微小可行空间(Tiny Feasible Space)”**中。这个离散空间非常小,但因为有专家经验的背书,所以极为可靠。
- 初始化与少次迭代:算法使用拉丁超立方抽样(LHS)在这个微小空间内生成少量的初始样本(通常为 10 个)来初始化代理模型,随后在这个小范围内执行设定次数($C$ 次)的贝叶斯优化迭代。
- 阶段成果:通过几十次的快速试错,系统就能站在前人经验的肩膀上,迅速拿到一个极其有潜力的优质配置。
2. 细粒度阶段 (Fine-grained Stage):彻底排查“最优解”
任何通过缩小空间来提速的技术,都不可避免地会把一些真正最优解给漏掉。因此,在拿到了初步的优秀结果后,系统必须进行细致的兜底排查。
- 继承经验:细粒度搜索绝不是从零开始盲搜,它会直接继承在粗粒度阶段已经训练好的代理模型。这样模型一开始就具备了对哪些参数好、哪些参数坏的基础认知。
- 还原并优化全空间:此时,搜索范围扩大到了完整的参数空间。但为了防止模型“迷路”,系统会砍掉那些会引发崩溃的危险取值,并利用虚拟参数扩展把诸如“0代表禁用”这类特殊值纳入考量范围。
- 深入彻底探索:在这个被精心修剪过的异构大空间里,贝叶斯优化继续发力,不断探索未知区域或挖掘已知好区域,直到把用户给定的资源预算(比如最大耗时或最大迭代次数)耗尽,或者达到了预期的性能提升为止。
展望
1. 缺乏实用的在线调优机制(Online Tuning)
- 目前的不足:目前 GPTUNER 和大多数现有的自动调优方法一样,采用的是离线调优范式。也就是说,系统需要先克隆出一个完全一样的数据库副本在后台进行试错调优,找到满意的配置后再部署到真实的生产环境中。这种做法虽然安全,但克隆数据库需要消耗大量的系统资源。之所以现在很难直接进行“在线调优”,是因为在庞大的配置空间中采样时,一旦生成了危险的参数配置,可能会导致真实的生产数据库直接崩溃,这对于在线服务来说是灾难性的。
- 未来努力方向:作者计划在未来探索如何进一步利用领域知识来彻底排除那些会导致系统崩溃的危险配置,从而保障安全性,最终实现直接在生产环境进行的“在线调优”。
2. 拓展优化其他数据处理系统(Optimizing other Data Processing Systems)
- 目前的不足:目前 GPTUNER 主要集中在关系型数据库管理系统(如论文中实验的 PostgreSQL 和 MySQL)的参数调优上。
- 未来努力方向:作者指出,利用领域知识来增强黑盒优化算法(如贝叶斯优化)的这一核心思想是非常通用的。因此,在未来的工作中,他们计划将这套方法应用到更广泛的大数据处理系统中,例如 Apache Spark 和 Apache Flink。同时,他们也将致力于识别和解决将该系统迁移到这些新计算框架时所面临的独特挑战。