
决策树 Decision Tree
决策树
决策树是一种树形结构的分类和回归模型。每个内部节点表示一个属性测试,每个分支表示一个测试结果,每个叶子节点表示一个类别或一个数值预测。决策树通过递归地划分数据集来构建模型,直到满足某个停止条件为止。
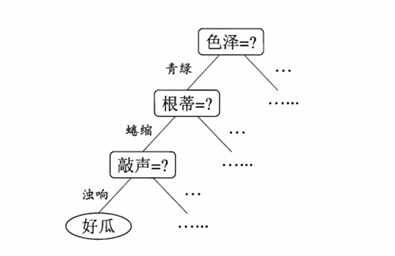
划分选择
关键是划分最优属性
结点的纯度要越来越高,三种度量节点纯度的指标:
信息增益
香农用“信息熵”来描述信源的不确定性
信息熵:当前样本集合D中第$i$类样本所占的比例为$p_i$,则D的信息熵定义为:
$$
H(D) = -\sum_{i=1}^{n} p_i \log_2 p_i
$$
H(D) 越大,数据集 D 的纯度越低;H(D) 越小,数据集 D 的纯度越高。对于二分类问题,n等于2.
假设离散属性A有V个不同的取值,按照A的每个取值划分数据集D后得到V个子集$D_1, D_2, …, D_V$,则属性A对数据集D的信息增益定义为:
$$
G(D, A) = H(D) - \sum_{v=1}^{V} \frac{|D^v|}{|D|} H(D^v)
$$
其中,$D^v$ 表示属性A取第v个值时,数据集D中对应的子集。
信息增益准则对可取值较多的属性有偏好,倾向于选择取值较多的属性进行划分。为什么这样说呢,因为下面的数据集如果将编号也作为属性的话,编号的信息增益是1,因为每个编号对应的样本都是纯的,但显然编号并不是一个有意义的划分属性。
参考以下数据集,其中“是否购买”是目标属性,其他属性是特征属性:
| 编号 | 年龄 | 是否试听 | 是否有优惠券 | 是否购买 |
|---|---|---|---|---|
| 1 | 青年 | 是 | 是 | 是 |
| 2 | 青年 | 是 | 是 | 是 |
| 3 | 青年 | 否 | 是 | 否 |
| 4 | 中年 | 是 | 是 | 是 |
| 5 | 中年 | 否 | 是 | 否 |
| 6 | 中年 | 是 | 否 | 是 |
| 7 | 老年 | 否 | 否 | 否 |
| 8 | 老年 | 否 | 是 | 否 |
首先选择第一个属性,根节点信息熵:
$$
H(D) = -\left( \frac{4}{8} \log_2 \frac{4}{8} + \frac{4}{8} \log_2 \frac{4}{8} \right) = 1
$$
计算年龄属性的信息增益:
$$
G(D, \text{年龄}) = H(D) - \left( \frac{3}{8} H(D^{\text{青年}}) + \frac{3}{8} H(D^{\text{中年}}) + \frac{2}{8} H(D^{\text{老年}}) \right)
$$
其中:
$$
H(D^{\text{青年}}) = -\left( \frac{2}{3} \log_2 \frac{2}{3} + \frac{1}{3} \log_2 \frac{1}{3} \right) \approx 0.918
$$
$$
H(D^{\text{中年}}) = -\left( \frac{2}{3} \log_2 \frac{2}{3} + \frac{1}{3} \log_2 \frac{1}{3} \right) \approx 0.918
$$
$$
H(D^{\text{老年}}) = -\left( \frac{0}{2} \log_2 \frac{0}{2} + \frac{2}{2} \log_2 \frac{2}{2} \right) = 0
$$
因此:
$$
G(D, \text{年龄}) = 1 - \left( \frac{3}{8} \times 0.918 + \frac{3}{8} \times 0.918 + \frac{2}{8} \times 0 \right) \approx 0.311
$$
同理,计算“是否试听”属性的信息增益:
$$
G(D, \text{是否试听}) = H(D) - \left( \frac{4}{8} H(D^{\text{是}}) + \frac{4}{8} H(D^{\text{否}}) \right)
$$
其中:
$$
H(D^{\text{是}}) = 0
$$
$$
H(D^{\text{否}}) = 0
$$
因此:
$$
G(D, \text{是否试听}) = 1 - \left( \frac{4}{8} \times 0 + \frac{4}{8} \times 0 \right) = 1
$$
增益率
增益率是信息增益的改进版本,旨在解决信息增益对取值较多属性的偏好问题。增益率定义为:
$$
GR(D, A) = \frac{G(D, A)}{IV(A)}
$$
其中,$IV(A)$ 是属性A的固有值,定义为:
$$
IV(A) = -\sum_{v=1}^{V} \frac{|D^v|}{|D|} \log_2 \frac{|D^v|}{|D|}
$$
增益率准则对可取值数目较少的属性有所偏好。因为IV(A)越大,说明属性A的取值分布越均匀,划分后的子集数量越多,增益率就会被打折扣。相反,如果属性A的取值较少,IV(A)较小,增益率就会相对较大,更有可能被选为划分属性。
基尼指数
基尼指数是 CART(Classification and Regression Trees)算法中使用的纯度度量指标。对于数据集D,基尼值定义为:
$$
Gini(D) = 1 - \sum_{i=1}^{n} p_i^2
$$
基尼指数定义为:
$$
Gini_index(D, A) = \sum_{v=1}^{V} \frac{|D^v|}{|D|} Gini(D^v)
$$
基尼指数越小,数据集 D 的纯度越高;基尼指数越大,数据集 D 的纯度越低。对于二分类问题,n等于2.
举个例子:
继续使用上述的信息增益中关于“年龄”划分的数据集:
总数据集 $D$ 有 8 个样本(4个购买,4个不购买),其基尼值为:
$$ Gini(D) = 1 - \left( \left(\frac{4}{8}\right)^2 + \left(\frac{4}{8}\right)^2 \right) = 0.5 $$
按“年龄”属性(分为青年、中年、老年)计算各个子集的基尼值:
-
$D^{\text{青年}}$ 有 3 个样本(2个购买,1个不购买):
$$ Gini(D^{\text{青年}}) = 1 - \left( \left(\frac{2}{3}\right)^2 + \left(\frac{1}{3}\right)^2 \right) = \frac{4}{9} \approx 0.444 $$ -
$D^{\text{中年}}$ 有 3 个样本(2个购买,1个不购买):
$$ Gini(D^{\text{中年}}) = 1 - \left( \left(\frac{2}{3}\right)^2 + \left(\frac{1}{3}\right)^2 \right) = \frac{4}{9} \approx 0.444 $$ -
$D^{\text{老年}}$ 有 2 个样本(0个购买,2个不购买):
$$ Gini(D^{\text{老年}}) = 1 - \left( \left(\frac{0}{2}\right)^2 + \left(\frac{2}{2}\right)^2 \right) = 0 $$
所以,“年龄”属性的基尼指数为:
$$ Gini_index(D, \text{年龄}) = \frac{3}{8} \times \frac{4}{9} + \frac{3}{8} \times \frac{4}{9} + \frac{2}{8} \times 0 = \frac{1}{3} \approx 0.333 $$
决策树算法:
- 决定分类属性
- 对目前的数据表,建立一个节点N
- 如果数据表中数据都属于一个类,那么N就是一个叶子节点,标记为该类,并返回
- 如果数据表中没有属性了,那么N就是一个叶子节点,标记为数据表中样本数最多的类,并返回
- 否则,根据属性选择方法选择一个最优属性A,并根据A的不同取值划分数据表,得到若干个子数据表
- 对于每个子数据表,递归调用步骤2-5,建立子节点,并将其连接到N上
剪枝:
预剪枝
因为决策树会不断往下分。如果不加限制,它可以:
把每个分支分得越来越细
直到一个叶子里只剩很少样本,甚至只剩 1 个样本
这样训练准确率会很高,但泛化能力往往下降。
通常把数据分成:
训练集 和 验证集
在某个结点上,比较:
不划分时,当前结点作为叶结点,在验证集上的精度
划分后,子树在验证集上的精度
如果划分后没有变好,就不要继续长树。
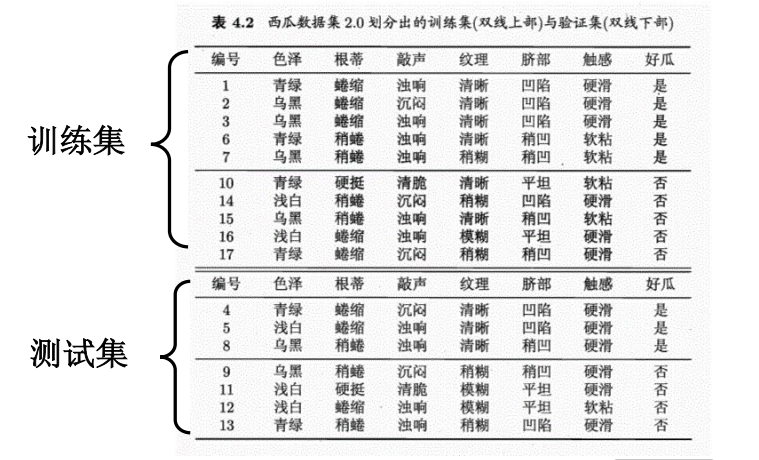
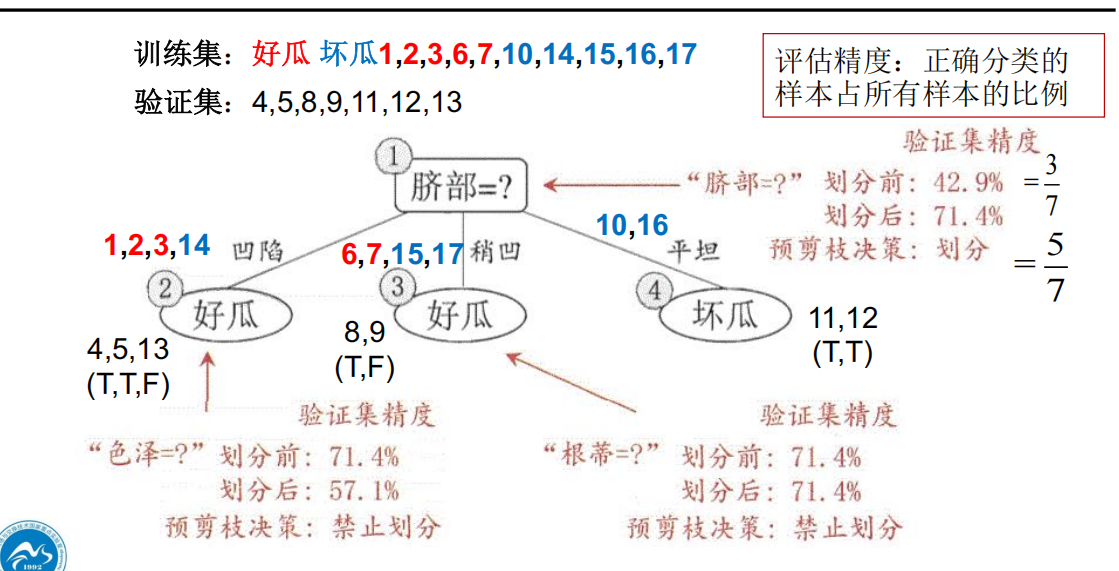
如上图,如果就在脐部结点停止划分,那么在验证集的概率是 3/7;如果继续划分,验证集上挑选到好瓜的概率是5/7(三个好瓜,两个坏瓜),所以就继续划分。
课件应该是将脐部提前剪枝后的节点表示为坏瓜,这样验证集里面是坏瓜的概率是3/7,
后剪枝
先得到完整树
从最底层非叶结点开始
比较:
保留子树时验证集精度
把这棵子树整体替换成一个叶结点时验证集精度
如果替换后更好,就剪枝
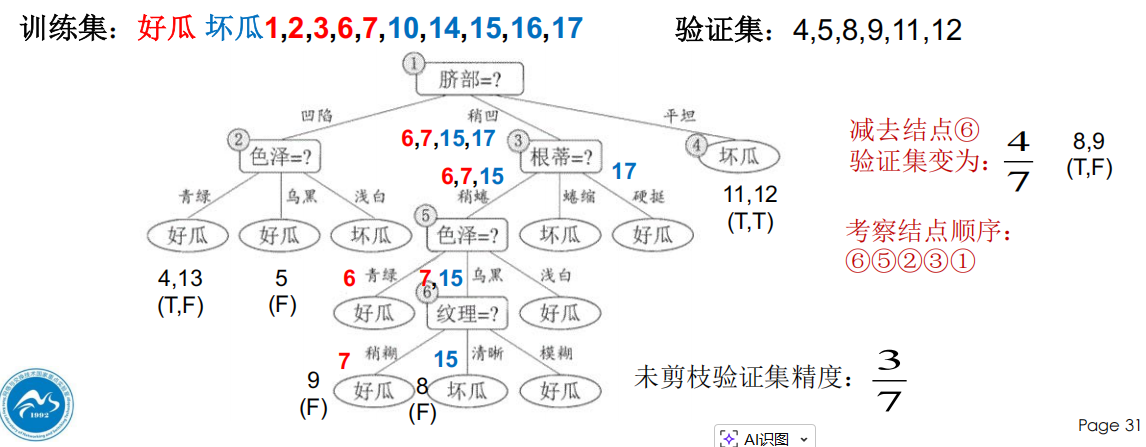
例如,未剪枝树的验证精度为:3/7
当考察某个底层结点(如结点⑥)时,剪掉它后验证集精度提升到:4/7
说明这一小段子树其实是在记训练集细节,对验证集没帮助,所以应该剪掉。
回归树:
连续属性离散化技术:
考虑n-1个切分点,计算每个切分点的信息增益,选择信息增益最大的切分点进行划分。
与离散属性不同,连续属性在后代结点中还可以再次被选为划分属性。
属性缺失:
在实际的数据集中,样本的某些属性往往由于各种原因导致缺失。决策树算法(如C4.5)通过赋予样本权重的方式来处理缺失值问题。
1. 属性值缺失时,如何选择划分属性、如何计算信息增益?
基本思路:仅根据没有缺失值的样本子集来判断属性的优劣。
给定训练集 $D$ 和属性 $A$,设 $\tilde{D}$ 表示 $D$ 中在属性 $A$ 上没有缺失值的样本子集。我们可以先基于 $\tilde{D}$ 计算出信息增益,然后再乘以一个比例系数 $\rho$:
$$
G(D, A) = \rho \times G(\tilde{D}, A)
$$
其中,$\rho = \frac{|\tilde{D}|}{|D|}$,即无缺失值样本占总样本的比例。这意味着一个属性上缺失值越多,其信息增益就会被打越大的折扣。
举个例子:
假设有 10 个西瓜样本,其中 8 个样本的“色泽”属性是已知的,2 个是缺失的。
首先,我们仅计算这 8 个已知色泽的样本在该属性上的信息增益,算出来假设为 $0.5$。
那么,在包含缺失值的这 10 个原始样本集上,“色泽”属性的最终信息增益就是:$\frac{8}{10} \times 0.5 = 0.4$。
2. 已经决定用某属性划分时,如果某样本在这个属性上的值缺失,怎么把它分到子结点?
基本思路:将该样本以不同的概率(权重)同时划分到所有子结点中。
假设样本在到达某结点时权重为 $w_x$(初始状态所有样本权重均为 1)。如果样本 $x$ 在属性 $A$ 上的取值已知,就将其直接划入对应的子结点,权重保持 $w_x$。
如果样本 $x$ 在属性 $A$ 上的取值缺失,则将它同时划入所有子结点,但在第 $v$ 个分支子结点中,该样本的权重会调整为:
$$
w_x^v = \tilde{r}_v \times w_x
$$
其中,$\tilde{r}_v$ 是无缺失样本集中,在属性 $A$ 上取值为 $v$ 的样本所占的比例。
直观来看,就是让同一个样本按照不同特征值出现的频率“分身”到各个分支继续参与后续的决策树构建。
举个例子:
假设当前结点最终选定了“色泽”作为划分属性,分为“青绿”、“乌黑”和“浅白”三个分支。
在当前所有色泽已知的样本中,属于“青绿”的样本占比 $50%$,属于“乌黑”的占比 $30%$,属于“浅白”的占比 $20%$。
此时有一个测试样本 $x$(到达当前结点时的权重为 $1$),但它的“色泽”值缺失了。那么样本 $x$ 应该去哪个分支呢?它会同时分到三个结点里:
- 进入“青绿”分支时,它带着的权重变为 $1 \times 50% = 0.5$;
- 进入“乌黑”分支时,它带着的权重变为 $1 \times 30% = 0.3$;
- 进入“浅白”分支时,它带着的权重变为 $1 \times 20% = 0.2$。
这样,缺失部分属性的样本依然能够依据其他已知样本的分布规律参与后续子结点的判断。