
D-Bot:基于LLM的数据库诊断系统
背景
数据库异常种类繁多,不可能用预定义的规则全面覆盖,往往依靠DBA的专业知识进行逐步分析。然而,人类DBA和令人望而生畏的异常问题之间存在巨大差距。
- 培训一个DBA需要大量的时间,
- 几乎不可能雇用足够的DBA来管理海量的数据库实例
- 在紧急情况下,DBA分析问题可能需要较长时间,在这期间会造成巨大的经济损失。
基于此,现在的数据库系统配备了半自动化工具,但是这些工具大多是(1.经验规则和小模型能力太窄)基于经验规则或者小型ML模型进行的,(2.泛化能力差)这些方法不能灵活地应用到变化的场景中。对于经验规则来说,重新根据新文档变换经验规则是很繁琐的,而ML模型需要重新设计输入指标和标签,并针对新场景重新训练模型。(3.缺乏像 DBA 一样的推理和交互能力)真实诊断需要递归地查看不同系统视图、结合工具结果调整下一步动作,而传统方法做不到这种“边诊断边探索”的过程。
因此,作者希望构建出具有以下三个特点的数据库系统:
- 精确诊断,可以制定诊断计划来准确地找到该优化的参数
- 节省费用和时间
- 通用性强,可以自己学习给定的文档,灵活分析未见的异常
即能够读文档学知识、知道当前该调用什么工具、能多步推理、还能给出最终报告。
最近大语言模型的发展为实现这些目标提供了可能,但是仍需解决以下问题:
- LLM 本身有理解和生成能力,但缺数据库知识与工具使用能力。
- 只给 LLM 一个问题不够,必须动态匹配相关知识和工具。
- 单次链式推理不稳定,需要树搜索和多专家协作来提高可靠性。
作者为了解决上述问题构建了Dbot:
- 首先,离线从文档中提取有用的知识块(基于摘要树的知识提取),并构建包含详细使用说明的工具层次结构,在此基础上初始化 LLM 诊断的提示模板。
- 其次,根据提示模板,通过匹配最相关的知识(知识匹配)和工具(工具检索)生成新的提示,LLM 可以利用这些提示获取监控和优化结果,从而进行合理诊断。
- 第三,引入了基于树状结构的搜索策略,引导 LLM 反思过去的诊断尝试并选择最有希望的一个,从而显著提高诊断性能。
- 最后,针对复杂的异常情况(如具有多个根源),提出了一种协作诊断机制,即多个 LLM 专家可以异步方式(如共享分析结果、进行交叉审查)进行诊断,以解决给定的异常情况。
贡献:
- 设计了一个基于 LLM 的数据库诊断框架,以实现精确诊断。
- 提出了一种诊断提示生成方法,通过与从文档中提取的相关知识进行匹配,以及利用微调嵌入模型检索工具,增强 LLM 执行诊断的能力。
- 提出了一种根本原因分析方法,利用基于树搜索的算法提高诊断性能,引导 LLM 进行多步骤分析。
- 提出了一种协同诊断机制来提高诊断效率,即多个 LLM 同时利用各自的领域知识分析问题。
系统设计
D-Bot 并不是一个单纯的对话机器人,而是一个标准的实时监控 -> 触发报警 -> 上下文画像组装 -> LLM 大脑深度推理 -> 输出修复方案的自动化闭环管线。
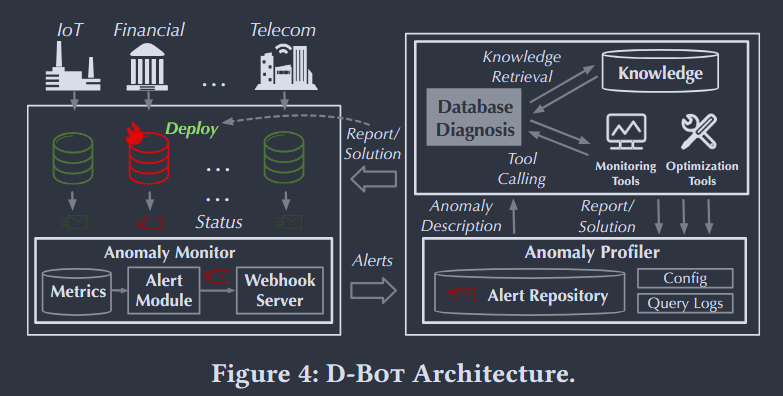
- 异常监控器 (Anomaly Monitor):底层模块持续收集各类 Metrics(如 CPU、内存、I/O 读写率)。一旦某项指标越界,触发预设规则,就会通过 Webhook Server 将警报(Alerts)发送出去。
- 异常画像器 (Anomaly Profiler):单一的警报往往信息碎片化。画像器接收警报后,会去抓取案发时间段内的数据库基础信息(如系统配置 Config)和查询日志(Query Logs),把它们拼接组装成一份结构化的“异常描述(Anomaly Description)”,作为后续诊断的输入基底。
- 数据库诊断核心 (Database Diagnosis):这是 D-Bot 的“大脑”。它首先在离线阶段准备好诊断知识和工具库。在在线阶段,动态检索最匹配当前画像的知识和工具,然后召唤单体 LLM(基于树搜索)或多个 LLM 专家(多智能体协作)进行多轮深度推理,最终输出一份详尽的诊断报告。
详解
离线知识与工具准备 (Offline Preparation)
目标:
- 把人类 DBA 读的冗长官方文档,变成 LLM 随时可用的结构化知识;
- 把 DBA 敲的代码脚本,变成 LLM 可调用的工具 API。
-
基于 Summary-Tree 的知识提取 ,长篇排错文档如果直接 Chunking 会导致上下文语意丢失。作者设计了三步提取法:
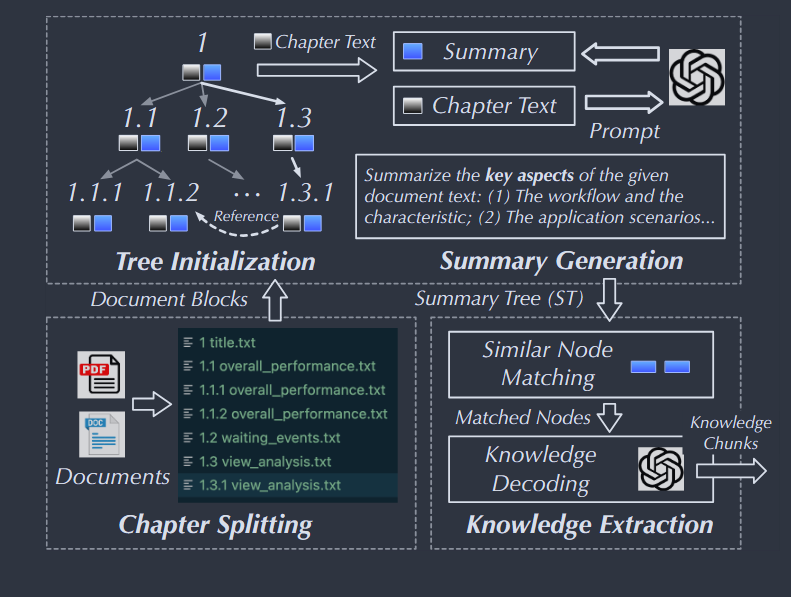
- 章节拆分:根据官方文档的章节层级关系进行切块,如果章节过大的话再递归拆小。
- 构建摘要树:把文档标题作为根节点,各切分块作为子节点,构成树结构。接着用 LLM 为每个节点生成一段“摘要(Summary)”作为文本索引。作者专门设计了 summarization prompt,让模型概括工作流、特征、应用场景等关键信息。
- 知识提取与聚类:LLM 拿着提示词遍历文档块及其子节点,遇到不确定的内容就去相似摘要的节点里找线索。
- 知识块格式化:最终提取出包含 “名称 (Name)”、“内容/影响 (Content)”、“相关指标 (Metrics)”和“排查步骤 (Steps)” 四要素的标准知识块。
- 去重与保留:知识块抽出来以后,系统会判断与已有知识是否重复。若 LLM 认为冗余概率低,就直接保留;若可能重复,则人工检查,只有确实没有新增信息才去掉。作者强调这样可以尽量覆盖诊断知识,同时减少冗余。
- 聚类:最后用embedding + DBSCAN 聚类,发现这些知识块大致按 root cause 类型聚集,比如 workload、query operator、index、memory、I/O 等。这个聚类结果后面直接用来定义“专家角色”
-
工具封装与注册 (Tool Preparation)
- 建立工具层级结构:作者把工具按层级组织成:categories → tools → APIs
例如:- optimization
- configuration tool
- heuristic_index_selection
- configuration tool
- optimization
- 给每个api写详细说明,包括这个api做什么,参数是什么,在什么场景下使用。例如索引推荐 API 会说明:根据查询模式和 workload 自动推荐降低成本的索引,参数包括查询频率、数据量、索引空间约束等。
- 动态注册 API:系统遍历工具模块,把 API 名称和说明注册进去,这样后续 LLM 在推理时就能调用这些工具。
- 建立工具层级结构:作者把工具按层级组织成:categories → tools → APIs
-
构建专家模板
不是只有一个通用 agent,而是依据知识聚类构造多个专家角色。
每个专家模板里包括:- 角色说明(例如 CPU expert)
- 任务说明
- 基本诊断步骤
- 可用知识范围
- 可用工具/API 列表
- demo examples
比如 CPU expert 会更擅长 CPU 相关问题,并能调用 cpu_usage_api、index_tuning_api 等。
这一步相当于把“知识分工”和“工具权限”绑定到不同 agent 上。
诊断提示词的动态生成(Prompt Generation)
当真实异常发生时,如果把所有知识和工具全塞给 LLM 会导致 Context 撑爆,且干扰信息过多。D-Bot 设计了在线生成上下文相关的prompt:
-
构造异常描述
输入包括:- 触发的 alert
- 发生时间
- 严重程度
- 状态信息
- 基础数据库信息
- 某些统计信息(如异常时段的查询统计)
这些内容由 Anomaly Profiler 从告警和数据库基础信息中生成。
-
知识检索:BM25 算法
检索当前的异常需要哪些知识来解决。
作者使用 BM25 对知识块做检索,但不是用原始文本全文匹配,而是主要基于知识块中的 Metrics 字段 来匹配当前异常涉及的异常指标。
其直觉是:如果当前观察到的异常指标与某个知识块常处理的指标相近,那么该知识块大概率有帮助。
论文中的 BM25 公式本质上是在给每个知识块打分:
- 某个异常指标在知识块里出现越多,分越高;
- 越稀有、区分度越高的指标,权重越大;
- 文档长度会做归一化,避免长块天然占优。
-
工具匹配:微调 Sentence-BERT
难点:API 的名字往往偏底层(某个 API 名叫
sort_remove,你单看名字并不知道它和慢查询有关),不包含明显的业务语义,BM25 查字面量会完全失效。方案:作者使用二元交叉熵损失函数(Cross-Entropy Loss)微调了一个 Sentence-BERT 模型:
$\mathcal{L}=-\sum_{i=1}^{n}\sum_{j=1}^{m}y_{ij}\log(p_{ij})+(1-y_{ij})\log(1-p_{ij})$训练数据是:
- 诊断上下文 $s_i$
- 工具 $t_j$
- 它们是否相关的标签 $y_{ij}$
微调后,系统将当前的异常上下文 $s$ 和 API 工具 $t_j$ 分别进行 编码 Embedding,然后通过计算两者的余弦相似度(Cosine Similarity) $\frac{emb(s)\cdot emb(t_j)}{||emb(s)||_2 ||emb(t_j)||_2}$,精准召回 Top-k 的最合适排障工具。
最后把工具名、函数说明、参数列表一起塞进 prompt。
-
加入历史消息:D-Bot 的诊断不是一次性完成,而是多轮进行。历史消息包括:
- 之前的 tool call
- 观察结果
- 已尝试的推理路径
- 已有中间判断
这些信息后面会供树搜索使用。
基于树搜索的推理引擎 (Tree Search Based Diagnosis)
为了克服原生 LLM 容易产生事实幻觉和“过早停止推理”的顽疾,作者将诊断过程建模为一个类似蒙特卡洛树搜索(MCTS)的马尔可夫决策过程。
-
树的初始化:每个节点代表 LLM 的一次动作(调用某个 API,或者得出一个中间结论),边代表动作的流向。
-
模拟执行:从根到叶不断进行推理,在选择节点时要进行UCT选择
UCT 探索算法:系统不盲目深搜,而是利用置信上限算法决定探索路径:
$UCT(n)=\frac{W(n)}{N(n)}+C\sqrt{\frac{2\ln N(p)}{N(n)}}$
其中 $N(n)$ 是当前节点访问次数,$N(p)$ 是父节点访问次数。第一项$\frac{W(n)}{N(n)}$表示获得投票数越多越靠谱,第二项$C\sqrt{\frac{2\ln N(p)}{N(n)}}$是探索奖励,访问越少的节点奖励越大,防止系统只盯着当前最优路径。最关键的 $W(n)$(获胜数)是由系统后台的多个“裁判 LLM”对叶子节点的排查结果有效性进行投票得出的。 -
节点评估与投票:
树搜索不是只靠一个 LLM 自己决定下一步,而是让多个评估 LLM 对叶节点投票,判断哪条路径更有前景。
评价依据包括:找到的 root cause 数量,是否准确,推理过程是否合理。
这样可以缓解单个 LLM 判断不稳定的问题。 -
反思与剪枝 (Reflection & Pruning):这是防幻觉的核心。每走一步,LLM 必须对自己刚刚的动作进行“反思(Reflection)”。这些 reflection 会附加到后继节点 prompt 中,帮助后续分支少走弯路。如果一个动作没有增加有效信息,该节点会被标记为 pruned。如果判定调用的这个 API 并没有拿到有用信息,就会触发节点剪枝(Prune node),直接回溯。这避免了算力浪费在无效的排查路径上。
协同诊断 (Collaborative Diagnosis)
数据库经常会遇到并发症(如慢查询引发 I/O 飙升,进而导致 CPU 打满)。单体 LLM 的 Context Window 和搜索深度有限,极易陷入局部最优(例如只看到了慢查询,忽略了 I/O 硬件瓶颈)。
-
专家角色划分:根据之前的知识聚类结果,系统预设了多个专家角色(如 CPU Expert、I/O Expert、Workload Expert)。每个专家都专注于自己领域的诊断,拥有特定的知识和工具权限。
-
专家分配:一个专职做 Routing 的 LLM 调度员,根据最初的异常描述,动态唤醒特定的领域专家(如Load_High → CPU Expert,Out_of_Memory → Memory Expert)。
-
异步发布-订阅机制:多个专家 Agent 并行开启树搜索。底层通信采用非阻塞的事件驱动模型。例如 CPU 专家查到了导致 I/O 飙升的线索,它会 Publish 这个发现;订阅了该状态的其它专家立刻感知,并利用这个新线索裁剪自己的搜索树。
-
交叉审查:
- 诊断摘要:因为单个专家的轨迹很长,先把每一步动作、结果逐步压缩成 running summary。这样别的专家 review 时不需要看整条原始轨迹。
- 审查建议:每个专家根据其他专家的结果给出纠错或补充建议。例如指出“根因过于宽泛”“缺少关键证据”“忽略了某个配置项”。
- 诊断修正:被审查的专家根据建议调整自己的诊断结论,必要时重新调用工具补充证据。
-
最终报告整合:当所有专家都完成诊断后,系统会把他们的结论进行整合,形成一份全面的诊断报告。
- 标题
- 异常时间
- 异常描述
- 根因
- 解决方案
- 诊断过程摘要
模块概览:
| 模块 | 功能 | 与其他模块的协同 |
|---|---|---|
| Anomaly Monitor | 持续监控数据库,触发告警 | 把 alert 发给 Anomaly Profiler |
| Anomaly Profiler | 把 alert + 基础 DB 信息整理成异常描述 | 给后续 prompt generation 提供输入 |
| Document Learning | 从文档抽取知识块,构建总结树 | 产出知识库,供知识检索使用 |
| Tool Preparation | 整理并注册工具/API | 产出工具库,供工具匹配和执行使用 |
| Prompt Generation | 结合异常描述、知识、工具、历史消息生成 prompt | 是 LLM 进入推理前的核心拼装器 |
| Tree Search Diagnosis | 做多步推理、试错、回溯、投票、剪枝 | 单专家诊断的核心执行引擎 |
| Collaborative Mechanism | 多专家并行诊断、共享中间结果、交叉审查 | 用于复杂多根因场景 |
| Report Generation | 汇总结果输出最终报告 | 面向用户/DBA 使用 |
展望
- 诊断排查的覆盖范围有限:D-Bot目前的诊断主要聚焦在数据库系统内部的瓶颈。文章明确指出,发生在应用程序端(application side)或网络端(network side)的异常被排除在了这项工作的范围之外 。
- 本地微调模型的泛化能力较弱:在使用特定样本微调本地开源大模型(如 Llama 2、CodeLlama、Baichuan 2)时,模型很容易对微调数据产生过拟合,有时甚至会丧失正常的文本生成能力,转而生成令人困惑的简短回复 。此外,这些本地化大模型对于未见过的、不熟悉的异常(例如由于训练样本数量较少而导致的删除操作异常)缺乏泛化能力,其表现极大地受限于微调样本的多样性 。个人觉得解决这个问题的根本还是数据集的质量。需要构造更多涉及多原因的复杂异常,让模型学会分析异常原因的思维链。
- 树搜索推理带来的时间与计算开销:基于树搜索的诊断成本会随着系统配备的诊断知识块和工具数量的增加而显著上升 。虽然系统通过多智能体协作机制提升了效率,但对于包含多个根因的相对复杂的异常,诊断依然需要几分钟到十几分钟的时间(例如处理一个复合异常耗时 5.38 分钟) 。或许可以根据异常的复杂程度来决定是否用多专家并行解决?比如简单异常单专家直接解决,中等异常双专家讨论,复杂异常多专家协同会诊,但是如何判断异常的复杂程度又是一个问题。
- 整个pipeline最后是输出分析报告,并没有更改真实的数据库来看效果如何。可以结合Agentune的验证方法,真正的修改参数再把反馈情况作为最开始的输入进行循环验证。