
LLMOpt——《A Query Optimization Method Utilizing Large Language Models》
背景
查询优化是数据库的关键任务,需要在海量策略中找到最高效的执行计划 。但传统方法依赖启发式搜索和代价预测,往往因为搜索空间太复杂或性能估计不准,导致选出来的计划不是最优的。
下图展示了传统查询优化器“先搜后选”的pipeline:
/1773275920985.png)
Candidate Searching:
对于n个表的查询,会产生$O(n!)$的复杂度,传统数据库采用动态规划或启发式算法来剪枝搜索空间。如图所示,可以向 DBMS 施加外部的“限制”以影响搜索过程。例如,一些方法会调整特定的数据库控制参数(Knobs),来启用或禁用特定的连接(Join)或扫描(Scan)操作,从而迫使优化器生成不同的候选计划集合。
容易出现的情况是,优化器在搜索过程中可能会错过一些潜在的高效计划,或者由于代价模型的不准确而选择了一个次优计划。这些问题导致了查询性能的下降,尤其是在复杂查询或大规模数据集上。即搜不全
Candidate Selection:
候选计划的结构和数值细节(例如表和过滤条件之间的关联方式,或特定的节点类型)会被编码为特征。图中的“代价模型”会评估这些特征,以近似计算查询执行所需的时间。传统的代价模型依赖于专家定义的规则和数据库统计信息(如基数估计),而现代基于机器学习的方法通常使用神经网络来更准确地预测执行开销。代价模型会比较所有候选计划的预测代价,并选择估计延迟最低的计划作为“最优计划”
但由于代价模型的局限性,选出来的计划可能并不是实际执行时性能最好的计划。这种情况在复杂查询或数据分布不均匀的情况下尤为常见。即选不准
LLMOpt 核心架构设计
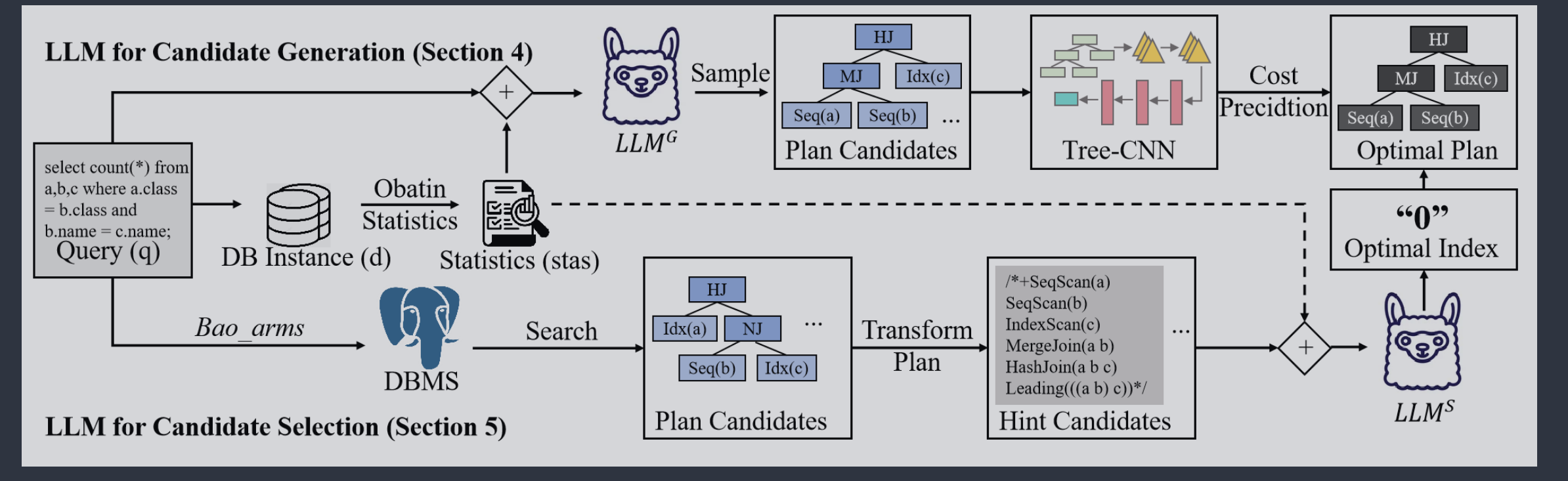
为了彻底解决传统流水线中“搜不全”和“选不准”的问题,这篇论文提出了 LLMOpt 框架。它的核心逻辑非常直接:用经过专门微调的大语言模型(LLM)分别替换掉传统的搜索算法和代价评估模型 。
用 $LLMOpt(G)$ 替代“候选搜索”:利用生成能力绕过启发式搜索
传统的优化器在庞大的 $O(n!)$ 空间里像走迷宫一样试错,而 $LLMOpt(G)$ 直接抛弃了启发式搜索,把“寻找计划”变成了一个文本生成任务 。
- 输入信息:系统会将用户的 SQL 查询 $q$ 以及相关的数据库统计信息 $stats(d, q)$(比如表的大小、最大最小值等)作为上下文输入给生成式大模型 $LLM^G$ 。
- 输出信息:最终输出一个最优的执行计划提示 $h^*$。
- 算法流程:
- 系统首先会根据当前的查询 $q$,去数据库实例 $d$ 中拉取相关的统计信息(统称为 stats) 。这些信息充当了“外部知识”,用于弥合大模型和传统优化器之间的信息差 。
- 把刚才拿到的 SQL 查询 $q$ 和统计信息 stats 一起打包,作为提示词(Prompt)喂给经过微调的生成式大模型 $LLM(G)$。大模型不会只给出一个答案,而是利用较高的采样温度($t=1$)进行多次采样(论文中提到了 16 次),从而生成一个包含多个不同提示(Hints)的候选集合 $H$ 。这就完全替代了传统数据库繁琐的启发式搜索过程。
- 系统开始遍历大模型刚才生成的候选集合 $H$ 中的每一个提示 $h$,通过 pg_hint_plan 插件,把提示 $h$ 强行塞给数据库 DBMS,让数据库返回对应的物理查询计划树 $p$,把这个计划树 $p$ 交给一个传统的深度学习代价模型(这里借用了 BAO 框架里的 Tree-CNN 模型) 。Tree-CNN 会根据树的结构和代价特征,预测出这个计划跑完大概需要多少秒(预测延迟 $c$)
- 记录预测延迟 $c$ 最小的那个提示 $h^*$,把它作为最终的最优计划提示返回给用户。
用 $LLMOpt(S)$ 替代“代价模型”:利用全局对比能力颠覆传统代价模型
遵循 BAO 的方法论,首先搜索各种候选计划,并将这些计划转换为序列化的提示。随后,使用 $LLM(S)$,一个列表级代价模型,通过生成相应的索引来选择最优提示。
- 输入信息:$(q, stats, H)$,与LLMOpt(G)不同的是,多了一个$H$参数,$H$ 是一批候选计划的文本序列。也就是说,这个模型是不生成候选计划的,而是直接对一批候选计划进行评估和选择。候选计划的生成是基于 BAO 的经典做法。它通过遍历各种底层的“控制开关”,强制传统数据库(DBMS)生成一系列结构不同的物理执行计划 $p$ 。然后进行序列化,把每一个生成的物理计划 $p$,通过 Transform_Plan 函数翻译成一维的文本提示(hint)$h$,并把它们塞进一个列表 $H$ 里。此时,$H$ 就是包含所有备选方案的“选项列表”。
- 输出信息:一个单独的 Token,代表最优计划在候选列表 $H$ 中的索引位置 $idx^*$。
- 算法流程:
- 与LLMOpt(G)一样,首先获取当前查询在数据库中的相关统计信息,作为大模型的辅助判断依据
- 用传统方法生成一批候选计划,并把它们转换成文本提示,形成候选列表 $H$。
- 把查询 $q$、统计信息 stats,以及整整一个列表的备选提示 $H$,全部打包一次性喂给微调过的大模型 $LLM^S$ 。大模型在内部做完全局对比后,只需要吐出一个极其简短的答案——一个代表索引位置的数字 Token(也就是 idx)。它不需要预测具体耗时几秒,只需指明“第几个选项最好”。
- 极速推理: 面对这批候选列表,$LLM(S)$ 只需要进行一次前向推理,并输出一个单独的 Token(即最优计划在列表中的索引 $idx^*$,比如输出“1”代表第二个计划最好) 。这种单次推理的设计大幅降低了耗时,提升了端到端的运行效率 。
实验结果
单独的使用LLMOpt(G)或者LLMOpt(S)执行表现都优于PG、BAO 和 HybridQO这三个baseline.
但是当把LLMOpt(G)和LLMOpt(S)结合起来,形成 LLMOpt(G+S) 的整体框架时,效果反而不如单独使用LLMOpt(S)
这是因为遭遇了“分布偏移”。$LLM^S$ 训练时见过的候选计划都是由数据库底层的 Bao_arms 生成的;但在实战时,突然让它去挑选 $LLM(G)$ 生成的全新风格的计划,导致裁判模型判断失准 。
展望
- 从 SFT 走向强化学习 (RL) 对齐
论文目前的微调手段仅停留在监督微调(SFT)阶段,即模仿数据集中表现最好的计划 。然而,查询计划的“执行延迟”是一个天然的、非可微的标量奖励信号(Reward Signal)。完全可以引入强化学习机制。使用真实的数据库执行时间作为 Reward,通过PPO或者更轻量级的GRPO算法,直接优化 $LLM^G$ 的生成策略。这样模型就不再是单纯“模仿”历史最优,而是能够自主探索出人类未曾设想的高效执行路径。 - 打通 Text-to-SQL 到执行的端到端链路
目前该系统仍需要传入解析好的结构化查询(SQL 抽象语法树特征)。未来可以考虑使用同一个大模型基座,将自然语言转 SQL 与 SQL 到物理计划(Hint 生成)结合在一起,训练一个统一的 AI4DB 基础模型。 - 解决 $LLMOpt(G+S)$ 的分布偏移
为了让“最强生成”与“最强裁判”真正结合,可以在 SFT 阶段采用联合训练,或者在微调 $LLM^S$ 时,有意掺入 $LLM^G$ 在不同训练阶段生成的候选集作为负样本,以此增强裁判模型的鲁棒性与泛化能力。