
参数调优《AgentTune》
概述
现有方法通常需要数百次工作负载重放或依赖海量训练数据,导致调优效率低下或准备成本高昂。此外,这些方法还面临生成无效配置的风险,可能导致性能下降甚至数据库崩溃。
- 调优效率低。基于机器学习(ML)的方法,通常需要数百次迭代才能收敛到理想的配置。每次迭代都涉及在数据库管理系统(DBMS)上执行工作负载(即工作负载重放),导致调优过程可能持续数小时。尽管大语言模型(LLM)辅助的方法实现了更快的收敛,但它们仍受限于基于机器学习的参数调优器固有的低效性。
- 可靠性低。尽管基于机器学习(ML)的调优通过平衡探索与利用来避免局部最优解,但它经常产生无效配置——即那些导致性能低于默认水平甚至使数据库管理系统(DBMS)崩溃的配置。同样,初步研究表明,直接使用大语言模型(LLMs)进行参数推荐可能会导致不安全的值(例如,过小的缓冲池大小),这源于幻觉和有限的数值推理能力等问题。这些问题可能导致调优过程中的资源耗尽或系统不稳定。
- 准备工作耗费大量资源。为了提高效率,许多基于机器学习(ML)和大型语言模型(LLM)的方法利用历史调优数据进行模型初始化、缩小配置空间或微调端到端参数调优器。然而,收集这些数据既耗时又耗费资源。例如,OtterTune 每个 DBMS 需要超过 3 万次试验,而 E2ETune 需要近 3000 个 <工作负载,合适配置> 样本。收集这些数据涉及在真实机器上运行工作负载,通常需要数天甚至数周的时间。此外,由于数据分布偏移,预训练模型往往难以泛化到新环境(例如不同的硬件或 DBMS 引擎),从而需要进行昂贵的重新训练以完成适配。
大语言模型针对参数调优基于智能体的框架关注度有限
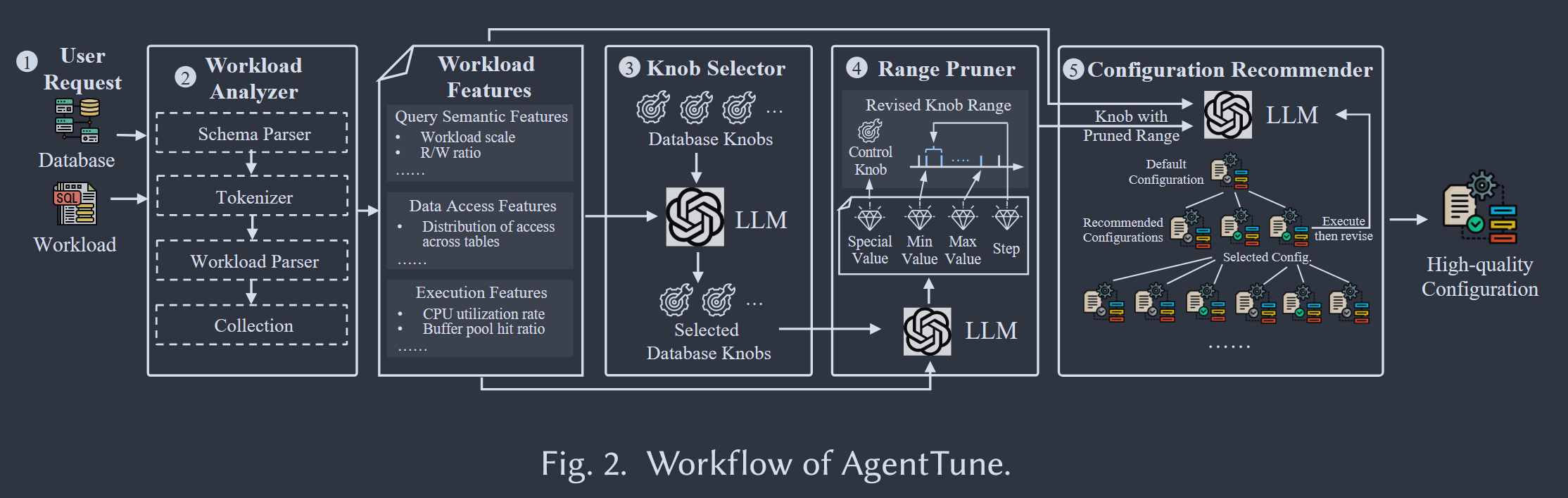
核心创新点在于完全由大语言模型(LLM)驱动且基于智能体的设计,首个由大语言模型(LLM)驱动的基于智能体的参数调优框架。
AgentTune 将调优过程分解为四个专门的智能体:工作负载分析器(Workload Analyzer)、参数选择器(Knob Selector)、范围剪枝器(Range Pruner)和配置推荐器(Configuration Recommender),每个智能体负责一个特定的子任务。这些智能体通过结构化的提示词链进行协作。
AgentTune,这是一种新型的、由大语言模型(LLM)驱动的基于智能体的框架,旨在实现高效且可靠的数据库参数调优,且无需准备大量的训练数据。AgentTune 将整体调优任务分解为四个关键子任务,每个子任务由一个专用智能体负责:核心的配置推荐器(Configuration Recommender)负责生成参数值,并由三个辅助智能体提供支持,分别是工作负载分析器(Workload Analyzer)、参数选择器(Knob Selector)和范围剪枝器(Range Pruner)。这些智能体共同模拟了资深数据库管理员(DBA)的行为与决策过程。
具体而言,在给定工作负载的情况下,
- 负载分析器(Workload Analyzer)通过解析工作负载及相关的数据库管理系统(DBMS)设置来提取关键特征,从而指导后续的调优过程。
- 参数选择器(Knob Selector)根据定义的范围剪枝器(Range Pruner)识别出影响最显著的参数,并确定有效范围以规避不安全配置。
- 配置推荐器(Configuration Recommender)采用一种新颖的基于树的迭代过程来生成高性能配置。该过程始于默认的参数配置。在每次迭代中,大语言模型(LLM)根据 DBMS 的反馈优化配置,并生成多个新的候选配置。
- 接着,利用创新的基于质心距离的排序机制对候选配置进行优先级排序,并筛选出前 k 个自洽性最高的候选配置以开启新一轮迭代。
通过利用 DBMS 反馈,该迭代过程能够快速收敛至高质量配置,其方式类似于人类数据库管理员(DBA)的迭代,从而实现了极高的效率。此外,由于 AgentTune 由提示工程和基于规则的工具驱动,在适应新环境时仅需极少的准备工作。例如,AgentTune 可以在不同的机器或 DBMS 平台之间实现无缝部署,而无需重新训练或进行大规模的数据收集。
详细架构介绍
负载分析器
负载分析器(Rule-based Agent)对输入负载进行总结,使其适用于大语言模型(LLM)的处理,在确保保留足够调优信息的同时,降低与 LLM 相关的处理成本。提取的特征分为两类:静态特征(如查询语义和数据访问特性)和动态特征(如内部指标和查询执行统计信息)。这反映了人类数据库管理员(DBA)所采取的方法,他们通常关注高层级的负载特征。
传统的负载分析有以下不足:
(1) 过度抽象:部分技术采用基于神经网络的表示或二进制编码方案,导致生成的高维特征对大语言模型(LLM)而言缺乏语义可解释性。
(2) 描述不足:其他方法将工作负载简化为原始描述符(如工作负载类型),未能为大语言模型驱动的决策提供充足的上下文信号 。
(3) 冗余:部分方法在提示词中包含原始 SQL 查询,导致输入过长,增加了大语言模型的处理成本,并存在超出 Token 限制的风险 。
查询语义特征描述了工作负载中 SQL 语句的特性。
数据访问特征刻画了工作负载与数据库模式schema及访问模式之间的交互方式。
执行特征捕捉了特定配置下数据库管理系统(DBMS)的当前状态。
由工作负载分析器 (Workload Analyzer) 生成的工作负载特征,包括静态特征(查询语义和数据访问)和动态特征(执行指标)。
| 查询语义特征 (Query Semantic Features) | 数据访问特征 (Data Access Features) | 执行特征 (Execution Features) |
|---|---|---|
| • 工作负载规模 • 读/写比率 • 每个查询的平均表数 • 每个约束子句的平均逻辑谓词数 • 每个查询的平均聚合函数数 • 每个查询的平均 GROUP BY 操作数 • 每个结果集的平均投影属性数 |
• 跨表的访问分布 • 跨列的访问分布 • 被查询列的值范围分布 • WHERE 子句中比较约束类型的比例 • 涉及排序的查询中升序与降序操作的比例 |
内部指标 (Inner Metrics)• CPU 利用率 • 缓冲池命中率 • 磁盘 I/O 吞吐量 查询执行统计信息 (Query Execution Statistics)• 延迟分布 • 事务吞吐量 • 结果集基数 • 锁争用持续时间 |
为了提取这些特征,我们的框架首先通过模式解析器从配置文件中处理数据库模式。随后,分词器tokenizer模块利用正则表达式对 SQL 语句进行分词。分词后的输出被传递给负载解析器,该解析器通过构建语法树来识别表名和列名等关键组件。接着,特征收集模块计算并聚合语义及数据相关特征。最后,将提取的信息与解析后的模式进行交叉验证,以确保一致性和完整性。为了最小化大语言模型(LLMs)记忆的内部知识所产生的影响,我们通过省略特定的负载名称(例如 TPC-C、JOB)来对负载特征进行匿名化处理。
参数选择器
参数选择器(LLM-based Agent)用于识别对当前工作负载影响最大的参数。现代数据库管理系统(DBMS)包含数百个参数,但影响最显著的参数会随工作负载的不同而显著变化。例如,参数 innodb_buffer_pool_size 对 OLTP 工作负载至关重要,但在 OLAP 场景中相关性较低。参数选择器利用 LLM 选择与工作负载相关的重要参数,从而在保持调优效果的同时提高优化效率。
传统方法依赖基于机器学习的算法来识别关键参数,通常需要在不同负载和配置下采集数百至数千个训练数据样本。最近,一些新兴方法利用大语言模型(LLMs),通过结合外部参数调优知识来识别可调参数,展现出优于传统机器学习技术的性能。然而,这些方法仍给用户带来了沉重的负担,要求其手动从官方文档、用户手册和社区帖子等来源搜集相关的参数调优知识。这种对人工干预的依赖限制了它们有效适应新环境的能力。
在提示词中添加以下四个部分:
- 任务描述(Task Description)规定了 LLM 的目标,即在给定上下文中选择最关键的参数
- 候选参数(Candidate Knobs)提供了数据库引擎中可用候选参数的详细信息,包括它们的默认范围、类型和描述。这些细节可以从官方文档中轻松获取。为了消除 LLM 预训练中可能存在的偏差,我们对框架中使用的所有参数名称进行了匿名化处理。
- 工作负载与数据库信息(Workload and Database Information)包括由工作负载分析器(Workload Analyzer)模块提取的关键特征,以及数据库内核和硬件规格。
- 输出格式定义了 LLM 响应的所需结构。具体而言,模型被要求以规范的 JSON 格式列出所选参数(knobs)的序号。
Prompt
1 | Task Description: Select the 20 most important knobs from the provided for the current tuning task in order to optimize the throughput metric. |
范围剪枝器
Range Pruner(LLM-based Agent)通过细化参数(knob)取值范围、迭代粒度和特殊情况值来优化调优空间。它利用基于 LLM 的智能体处理工作负载特征和已识别的参数,以确定每个所选参数的关键取值范围。重要的是,LLM 生成的建议与基于规则的约束相结合,从而提升了效率和可靠性。
有以下需要克服的问题:
(1) 过于宽泛的默认范围:默认范围通常被设计得尽可能广泛。例如,MySQL 中最关键的参数之一 innodb_buffer_pool_size 在 64 位平台上的默认范围为 $[0, 2^{64} − 1]$ 字节。该参数控制缓冲池的大小(以字节为单位),即 InnoDB 缓存表和索引数据的区域。然而,超出可用内存的范围是无效的,并可能导致 DBMS 在启动时失败。
(2) 微小调整的无效性:对于取值范围较大的参数,微小的改变对性能的影响通常可以忽略不计。此外,DBMS 暴露的离散参数在量级上可能存在巨大差异。有些参数仅有 10 个可选值,而另一些则跨越数百万个。例如,调优 innodb_log_buffer_size 时,67,108,864 字节与 67,109,888 字节(仅 1KB 之差)之间并无实质性的性能差异。
(3) 特殊值的存在:某些配置参数(knobs)支持特殊值(例如 -1 或 0),这些值会触发特定的数据库行为。传统的基于机器学习(ML)的方法难以处理这些值,因为这些方法通常依赖于平滑的输入-输出映射,且往往会忽略此类特殊语义,而这些知识通常仅能通过技术手册或专家经验获取。
范围剪枝器首先将所有选定的参数及其对应的默认范围作为统一的输入上下文呈现给 LLM。这种设计使 LLM 在建议优化后的取值范围时,能够全面地推理参数之间潜在的相互依赖关系。根据 LLM 的输出,搜索空间将使用更新后的、更窄的范围进行重构。对于每个参数,剪枝后的范围由四个要素定义:上限、下限、特殊值和迭代粒度。上限和下限定义了允许的取值范围,而特殊值则明确指示了任何异常设置及其语义。迭代粒度规定了每个参数调优步骤的建议调整幅度,从而避免了后续参数推荐中因调整幅度过小而导致的无效性。
1 | Task Description: Given the knobs along with their suggestion and tuning task information, your job is to offer intervals for each knob that may lead to the best performance of the system and meet the hardware resource constraints. In addition, if there is a special value (e.g., 0, -1, etc.), please mark it with “special value”. |
参数推荐器
参数推荐器(LLM-based Agent)。引入了一种新颖的基于树的搜索框架,用于为给定的工作负载识别合适的配置。与传统的顺序调优方法不同,我们的方法在每次迭代中生成多个候选配置,并选择前 k 个进行进一步细化,从而形成树状结构。为了提高效率,在迭代过程中采用了排序机制,以避免评估每个中间候选配置。
1 | Task Description: Recommend optimal knob configuration based on the given information in order to optimize the throughput metric. |
下面这个例子具体介绍了算法的执行过程:
在 AgentTune 的默认设置中,束宽(Beam width)设为 $k=2$,每次 LLM 扩展生成的子节点数为 $R=3$。
- 初始阶段:根节点 (Root Node)
- 当前状态: 调优开始时,系统将数据库的默认配置作为初始的根节点放入当前的束(Beam)中 。
- 具体数据: 假设这是一台 16 GB 内存的 MySQL 机器 。此时默认配置的关键参数可能为
innodb_buffer_pool_size: 128 MB,innodb_write_io_threads: 4。 - 初始反馈: 在此默认配置下运行 SYSBENCH 工作负载,记录反馈。例如,吞吐量仅为 17.25 TPS (Transactions Per Second)。
- 节点扩展:LLM 生成候选配置 (Candidate Generation)
系统将当前节点的信息组装成 Prompt 输入给大语言模型,要求它根据反馈生成 $R=3$ 个改进后的候选配置 。
- Prompt 组装示例^^:
- 当前配置:
innodb_buffer_pool_size: 128 MB - 数据库反馈: 吞吐量:17.25 TPS;内部指标:缓存命中率低,磁盘 I/O 争用严重。
- 参数范围约束:
innodb_buffer_pool_size的上限已被“范围修剪器”限制为系统最大可用内存的合理比例(如不超过 14 GB) 。
- 当前配置:
- LLM 的 3 个输出分支(模拟):
- 候选 A: 认为缓存太小,直接加满。
innodb_buffer_pool_size: 14 GB,innodb_write_io_threads: 8 - 候选 B: 比较保守的增加。
innodb_buffer_pool_size: 8 GB,innodb_write_io_threads: 6 - 候选 C: 折中方案。
innodb_buffer_pool_size: 12 GB,innodb_write_io_threads: 8
- 候选 A: 认为缓存太小,直接加满。
- 规则过滤 (Rule-based Filtering)
AgentTune 会对这 3 个候选进行白盒规则检查 。
- 具体数据: 假设系统检测到此时机器内存剩余不足 14 GB,候选 A 被判定为不安全配置(可能会导致 OOM 崩溃),因此被直接丢弃。剩下的有效候选为 B 和 C。
- 核心计算:基于质心距离的排序 (Centroid-Distance-Based Ranking)
此时我们需要从多个候选节点中选出 Top-$k$($k=2$)进入下一轮 。假设当前候选池中有 3 个有效配置(此处为了方便计算排名,我们假设 LLM 这一轮总共生成了三个有效配置 X, Y, Z):
- 配置 X: 线程数 4,缓冲池 8 GB
- 配置 Y: 线程数 8,缓冲池 10 GB
- 配置 Z: 线程数 12,缓冲池 12 GB
计算步骤:
-
算均值: 线程数均值 = $(4+8+12)/3 = 8$;缓冲池均值 = $(8+10+12)/3 = 10$ GB。
-
算偏差排名(越接近均值排名越靠前):
- 配置 X: 线程距离均值差 4(排名 2),缓冲池距均值差 2(排名 2)。总分:2 + 2 = 4
- 配置 Y: 线程距离均值差 0(排名 1),缓冲池距均值差 0(排名 1)。总分:1 + 1 = 2
- 配置 Z: 线程距离均值差 4(排名 2),缓冲池距均值差 2(排名 2)。总分:2 + 2 = 4
-
筛选: 配置 Y 总分最低(2分),最接近大模型的“共识质心”,它会被优先选中 。接着 X 和 Z 同分,系统随机选取一个(假设选了 Z)。最终 Y 和 Z 成为新的束 (Beam)。
-
执行反馈与记忆窗口 (Execution & Memory Window)
- 工作负载重放: 将选出的配置 Y 和 Z 分别应用到数据库,重启并运行测试。
- 具体数据: 假设配置 Z (
innodb_buffer_pool_size: 12 GB,innodb_write_io_threads: 8) 让吞吐量飙升到了 230 TPS。 - 记忆窗口更新: 这个“配置 Z $\rightarrow$ 230 TPS”的成功经验会被存入 记忆窗口 (Memory Window)。在下一轮迭代时,Prompt 中会包含这句话:“历史最佳记录:在配置 Z 下,我们达到了 230 TPS”。这相当于给了 LLM 一个 Few-shot 提示,告诉它“这个方向是对的,请在此基础上继续微调”。
- 迭代与收敛
这个“生成 $\rightarrow$ 过滤 $\rightarrow$ 排序 $\rightarrow$ 执行反馈”的过程会在树状结构中不断循环 。
- 最终结果: 论文中的真实数据显示,经过 23 次这样的重放迭代(即 $T_{opt} = 23$),AgentTune 在 SYSBENCH 上找到了吞吐量高达 268.03 TPS 的最佳配置(比默认的 17.25 TPS 提升了 15 倍以上) 。此时如果继续迭代 10 次都没有更高分数,系统就会触发早停,输出最终结果。
尚可解决的问题
- 目前,AgentTune 主要利用性能指标和执行特征作为数据库调优的反馈信号。引入更丰富的数据库反馈是进一步提升配置推荐器收敛性与有效性的一个具有前景的方向。例如查询执行计划的变化
- 对于包含大量查询的复杂负载,通常只有一部分代表性查询子集会显著影响数据库性能。因此,利用大语言模型(LLMs)进行负载压缩是一个极具前景的方向
- 参数搜索空间受限于大模型的上下文长度。文章在探讨旋钮(参数)数量的消融实验时提到,由于 GPT-4 的上下文长度限制,AgentTune 目前无法一次性探索更大的参数空间。
- 虽然更多的参数可以带来性能的提升,但同时也会导致提示词(Prompt)过长、计算成本增加以及调优时间变长 。因此实验中主要选择 20 个最重要的参数进行调优 。
- AgentTune本质上还是一种离线策略的方案