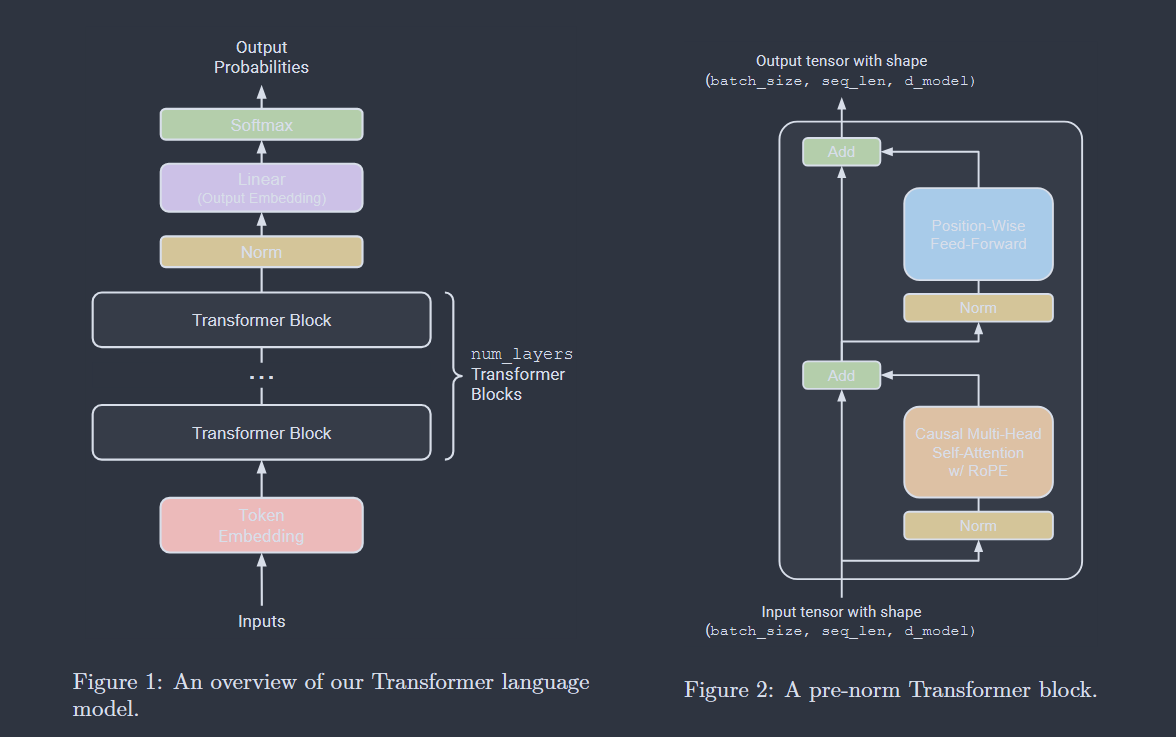
本文讲解的是现代大模型(如GPT-4、Gemini等)背后的核心架构——Transformer。与2017年之前的Transformer架构相比,现代大模型在细节上有很多改进和优化。我们将从整体架构、核心组件(如Embedding层、Multi-Head Attention、Feed-Forward Network等)以及训练技巧等方面进行详细讲解。
Embedding层
Transformer模型的输入首先通过一个Embedding层将离散的词汇转换为连续的向量表示。这个过程可以看作是将每个词映射到一个高维空间中,使得语义相似的词在这个空间中也相近。
1 2 3 4 5 6 7 8 9 10 11 12 class Embedding (nn.Module): def __init__ (self, num_embeddings, embedding_dim, device=None , dtype=None ): super ().__init__() self .weight = nn.Parameter( torch.empty(num_embeddings, embedding_dim, device=device, dtype=dtype) ) torch.nn.init.trunc_normal_(self .weight, mean=0 , std=1.0 , a=-3 , b=3 ) def forward (self, token_ids ): return self .weight[token_ids]
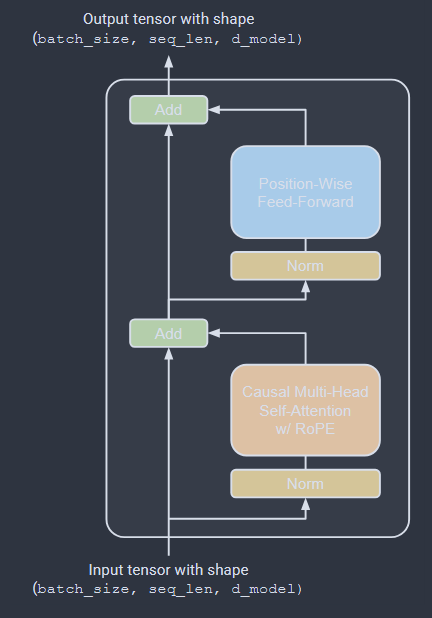
transformer block
每个 Transformer 块接收形状为 (batch_size, sequence_length, d_model) 的张量作为输入,并输出完全相同形状的张量 。它主要由两个带有残差连接的子层(Sub-layers)组成 :
1. 因果多头自注意力子层 (Causal Multi-Head Self-Attention)
前置归一化 :在进行核心计算前,首先对输入应用均方根层归一化(RMSNorm)。核心计算 :执行因果多头自注意力计算。在这一步中,模型会使用因果掩码(Causal Masking)以防止模型关注到序列中未来的 Token 。同时,会在查询向量(Query)和键向量(Key)上应用旋转位置嵌入(RoPE),以此来注入相对位置信息 ^^。残差连接 :将归一化前的原始输入与注意力机制的输出直接相加。其数学表达形式为:y = x + MultiHeadSelfAttention(RMSNorm(x))。
2. 位置前馈网络子层 (Position-Wise Feed-Forward Network)
前置归一化 :与上一个子层类似,在进入前馈网络前,先对上一步的输出 y 应用 RMSNorm。核心计算 :将数据输入前馈网络。现代架构摒弃了原始的 ReLU 激活函数,转而采用了无偏置项(no biases)的 SwiGLU 机制(结合了 SiLU 激活函数与 GLU 门控机制)进行非线性特征变换 。残差连接 :将该子层的输入与前馈网络的输出再次相加,得出该 Transformer 块的最终输出结果 。
RMSNorm(Root Mean Square Layer Normalization)。
传统的layer normalization会计算输入张量的均值和标准差,并使用这些统计量来归一化输入。相比之下,RMSNorm 只计算输入张量的均方根值,并使用这个值来进行归一化。这种方法在实践中被证明能够提供与传统 Layer Normalization 相似的性能,同时减少了计算复杂度。
$$
$$
$x$ :输入张量。$d$ :特征维度(即 d_model)。$\epsilon$ :一个极小的常数(通常为 $10^{-5}$ ),防止分母为零。$g$ :可学习的增益参数(gain),初始值为全 $1$ 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class RMSNorm (nn.Module): def __init__ (self, d_model, eps=1e-5 , device=None , dtype=None ): super ().__init__() self .eps = eps self .gain = nn.Parameter(torch.ones(d_model, device=device, dtype=dtype)) def forward (self, x ): in_dtype = x.dtype x = x.to(torch.float32) rms = torch.sqrt(torch.mean(x ** 2 , dim=-1 , keepdim=True ) + self .eps) x = x / rms x = x * self .gain return x.to(in_dtype)
Linear层
$$
现代大模型(如 Llama、PaLM)发现,去掉线性层里的加法偏置项 $\beta$ 几乎不会降低模型能力,反而能提升训练速度并省下宝贵的显存。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 import torchimport torch.nn as nnimport mathclass Linear (nn.Module): def __init__ (self, in_features: int , out_features: int , device=None , dtype=None ): """ 构造一个无偏置项的线性变换层。 参数: in_features: 输入特征的维度 out_features: 输出特征的维度 """ super ().__init__() self .weight = nn.Parameter( torch.empty((out_features, in_features), device=device, dtype=dtype) ) std = math.sqrt(2.0 / (in_features + out_features)) nn.init.trunc_normal_(self .weight, mean=0.0 , std=std, a=-3 *std, b=3 *std) def forward (self, x: torch.Tensor ) -> torch.Tensor: """ 前向传播函数。 参数: x: 形状为 (*, in_features) 的张量,可以有任意多个前置批次维度 返回: 形状为 (*, out_features) 的张量 """ return x @ self .weight.T
在 init 中计算 std = math.sqrt(2.0 / (in_features + out_features)) 是深度学习历史上一个非常伟大的洞察(Glorot 初始化):
如果权重一开始的数值太大,经过几次矩阵乘法,输出的特征值就会爆炸成天文数字,也就是“梯度爆炸”。
如果权重一开始的数值太小,乘几次之后,特征值就全部变成了 $0$,也就是“梯度消失”。
这个特定的数学公式 $\sigma = \sqrt{\frac{2}{d_{in} + d_{out}}}$ 刚好能够保证:数据进入线性层前后的方差(分布的离散程度)保持一致。加上 [-30, 30] 的强制截断,相当于给模型在起跑线上穿上了一层防弹衣,让它在训练初期的步伐无比稳健。
Position-Wise Feed-Forward Network
位置前馈网络(Position-Wise Feed-Forward Network)是Transformer架构中的一个重要组件,位于每个Transformer块的第二个子层。它的主要作用是对每个位置的特征进行非线性变换,以增强模型的表达能力。它的经典结构是:线性变换(升维)→ 激活函数 → 线性变换(降维)。FFN的三大核心作用
提供非线性能力(最根本作用)
问题:自注意力机制本质是加权求和,属于线性操作
FFN的解决方案:通过激活函数(ReLU、GELU等)引入非线性
重要性:没有非线性,无论堆叠多少层Transformer,整体仍等价于单层线性模型,无法学习复杂模式
对信息进行深度加工
多头注意力的角色:让词语之间“开会讨论”,收集全局信息
FFN的角色:让每个词语“独立深度思考”,消化和提炼信息
工作方式:对注意力层输出的每个位置表示进行独立、并行的深度处理
存储模型知识
参数量对比:在标准Transformer中,FFN的参数量通常占全层参数的2/3以上
作用:如同模型的“长期记忆”,存储从训练数据中学到的各种模式和规律
工作方式:通过大量参数学习特征之间的复杂组合关系
激活函数 (引入非线性):
ReLU(Rectified Linear Unit)
GLU(Gated Linear Unit)
定义:$GLU(x) = (xW_1) \odot \sigma(xW_2)$
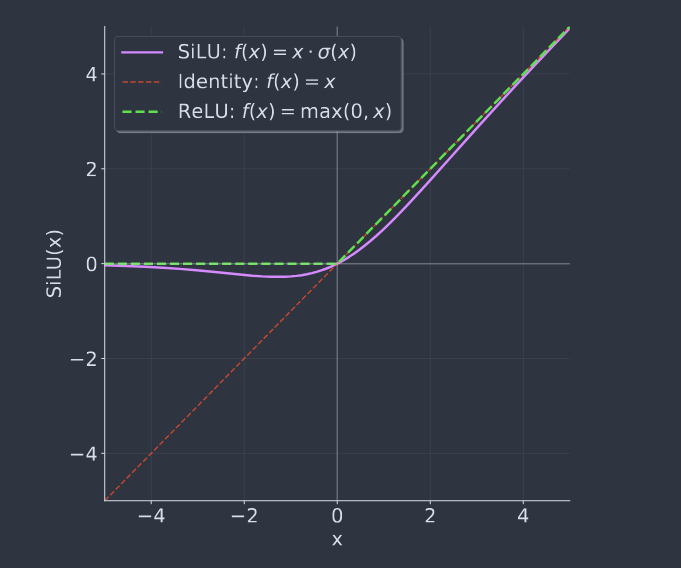
SiLU(Sigmoid Linear Unit,也叫 Swish)
定义:$f(x) = x \cdot \sigma(x)$,其中 $\sigma(x)$ 是 Sigmoid 函数,即 $\sigma(x) = \frac{1}{1 + e^{-x}}$。
此处我们实现的SwiGLU是SiLU和GLU的结合体,公式如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 import torchimport torch.nn as nnimport torch.nn.functional as Fclass FeedForward (nn.Module): def __init__ (self, d_model: int , d_ff: int ): """ 基于 SwiGLU 机制的位置前馈网络。 参数: d_model: 模型的隐藏层维度 (输入和最终输出的维度) d_ff: 前馈网络内部膨胀后的隐藏层维度 (通常是 d_model 的 8/3 倍左右) """ super ().__init__() self .w1 = Linear(in_features=d_model, out_features=d_ff) self .w3 = Linear(in_features=d_model, out_features=d_ff) self .w2 = Linear(in_features=d_ff, out_features=d_model) def forward (self, x: torch.Tensor ) -> torch.Tensor: """ 参数: x: 形状为 (batch_size, seq_len, d_model) 的张量 返回: 形状相同为 (batch_size, seq_len, d_model) 的张量 """ branch1 = F.silu(self .w1(x)) branch2 = self .w3(x) gated = branch1 * branch2 return self .w2(gated)
RoPE 旋转位置嵌入
在经典的 Transformer 中,位置编码是绝对的:模型强行给第 3 个词加上一个“我是编号 3”的向量。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 import torchimport torch.nn as nnclass RotaryPositionalEmbedding (nn.Module): def __init__ (self, theta: float , d_k: int , max_seq_len: int , device=None ): super ().__init__() self .d_k = d_k inv_freq = 1.0 / ( theta ** (torch.arange(0 , d_k, 2 , device=device).float () / d_k) ) positions = torch.arange(max_seq_len, device=device).float () freqs = torch.outer(positions, inv_freq) cos = torch.cos(freqs) sin = torch.sin(freqs) self .register_buffer("cos" , cos) self .register_buffer("sin" , sin) def _rotate_half (self, x ): x_even = x[..., ::2 ] x_odd = x[..., 1 ::2 ] x_rot = torch.stack((-x_odd, x_even), dim=-1 ) return x_rot.flatten(-2 ) def forward (self, x: torch.Tensor, token_positions: torch.Tensor ) -> torch.Tensor: """ x shape: (..., seq_len, d_k) token_positions shape: (..., seq_len) """ token_positions = token_positions.long() cos = self .cos[token_positions] sin = self .sin[token_positions] while cos.ndim < x.ndim: cos = cos.unsqueeze(1 ) sin = sin.unsqueeze(1 ) cos = torch.repeat_interleave(cos, 2 , dim=-1 ) sin = torch.repeat_interleave(sin, 2 , dim=-1 ) return x * cos + self ._rotate_half(x) * sin
缩放点积注意力
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 import torchimport mathdef scaled_dot_product_attention (query: torch.Tensor, key: torch.Tensor, value: torch.Tensor, mask: torch.Tensor = None ) -> torch.Tensor: """ 实现缩放点积注意力。 参数: query: 形状为 (batch_size, ..., seq_len, d_k) key: 形状为 (batch_size, ..., seq_len, d_k) value: 形状为 (batch_size, ..., seq_len, d_v) mask: 形状为 (seq_len, seq_len) 的布尔张量 (可选)。 True 表示参与注意力计算,False 表示该位置概率应为 0。 返回: output: 形状为 (batch_size, ..., seq_len, d_v) 的张量 """ d_k = query.size(-1 ) scores = query @ key.transpose(-2 , -1 ) scores = scores / math.sqrt(d_k) if mask is not None : scores = scores.masked_fill(mask == False , float ('-inf' )) attn_weights = torch.softmax(scores, dim=-1 ) output = attn_weights @ value return output
上一层pre-norm输入的tensor形状是(batch_size, seq_len, d_model),query、key、value的形状都是(batch_size, seq_len, d_k),(实际上value的最后一维可以不一样,但是默认一样)其中d_k通常等于d_model // num_heads。
$$
先计算Q和K的点积,得到一个形状为(batch_size,…, seq_len, seq_len)的分数矩阵。然后将这个分数矩阵除以$\sqrt{d_k}$进行缩放,最后通过softmax函数得到注意力权重,再乘以V得到最终的输出。
因果掩码处理,如果是训练阶段,mask是一个下三角矩阵,确保模型只能关注到当前词和之前的词;如果是推理阶段,mask会根据已经生成的序列动态调整,保证模型不会看到未来的词。
softmax函数将最后一维 的分数转换为概率分布attn_weights,确保最后一维所有权重加起来等于1。
最后乘以V的操作是将每个位置的值向量根据注意力权重进行加权求和,得到每个位置的最终输出表示(batch_size, …, seq_len, d_v)。
假设 seq_len 是 3(一共3个词)。
对于第 1 个词,attn_weights 的第一行可能是 [0.2, 0.7, 0.1]。
当这行数字去乘以 $V$ 矩阵时,它实际上是在做 加权求和 :
拿出 $V$ 里面第 1 个词特征的 20%
加上 $V$ 里面第 2 个词特征的 70%
加上 $V$ 里面第 3 个词特征的 10%d_v 的向量,这就是第 1 个词经过注意力机制洗礼后,最终输出的特征!
multihead_self_attention
多头自注意力机制的核心思想是:将输入的特征空间分成多个子空间(head),每个子空间独立地进行注意力计算,最后再将这些子空间的输出拼接起来,经过线性变换得到最终的输出。这种设计允许模型在不同的子空间中捕捉到不同类型的关系和模式,从而增强了模型的表达能力。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 from einops import rearrangeclass MultiHeadSelfAttention (nn.Module): def __init__ (self, d_model: int , num_heads: int ,rope_theta=10000 ,max_seq_len=2048 ): super ().__init__() assert d_model % num_heads == 0 , "d_model 必须能被 num_heads 整除" self .num_heads = num_heads self .d_k = d_model // num_heads self .W_q = nn.Linear(d_model, d_model, bias=False ) self .W_k = nn.Linear(d_model, d_model, bias=False ) self .W_v = nn.Linear(d_model, d_model, bias=False ) self .rope = RotaryPositionalEmbedding( rope_theta, self .d_k, max_seq_len, ) self .W_o = nn.Linear(d_model, d_model, bias=False ) def forward (self, x: torch.Tensor, token_positions: torch.Tensor ) -> torch.Tensor: batch_size, seq_len, _ = x.shape q = rearrange(self .W_q(x), 'b s (h d) -> b h s d' , h=self .num_heads) k = rearrange(self .W_k(x), 'b s (h d) -> b h s d' , h=self .num_heads) v = rearrange(self .W_v(x), 'b s (h d) -> b h s d' , h=self .num_heads) q = self .rope(q, token_positions) k = self .rope(k, token_positions) mask = torch.tril(torch.ones(seq_len, seq_len, device=x.device, dtype=torch.bool )) context = scaled_dot_product_attention(q, k, v, mask=mask) out = rearrange(context, 'b h s d -> b s (h d)' ) return self .W_o(out)
学完上面线性层,位置前馈网络,RoPE,缩放点积注意力,我们就已经掌握了Transformer架构的核心组件。接下来我们会把这些组件组合起来,构建完整的Transformer块。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 import torchimport torch.nn as nnclass TransformerBlock (nn.Module): def __init__ (self, d_model, num_heads, d_ff, max_seq_len ): """ 参数: d_model: 输入和输出的维度 num_heads: 多头注意力的头数 d_ff: 前馈网络 (SwiGLU) 的中间隐藏层维度 """ super ().__init__() self .norm1 = RMSNorm(d_model) self .norm2 = RMSNorm(d_model) self .attn = MultiHeadSelfAttention(d_model=d_model, num_heads=num_heads, max_seq_len=max_seq_len) self .ffn = FeedForward(d_model=d_model, d_ff=d_ff) def forward (self, x: torch.Tensor, token_positions: torch.Tensor ) -> torch.Tensor: """ 参数: x: 形状为 (batch_size, seq_len, d_model) token_positions: 形状为 (batch_size, seq_len) 返回: 形状相同的输出张量 """ x = x + self .attn(self .norm1(x), token_positions) x = x + self .ffn(self .norm2(x)) return x
transformer LM
将多个Transformer块堆叠起来,再加上后面几个层级组件(如输出层),我们就得到了一个完整的Transformer语言模型。nn.CrossEntropyLoss),而在推理阶段,我们也会直接对输出的logits进行采样或贪心解码,而不是先计算概率分布。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 class TransformerLM (nn.Module): def __init__ ( self, vocab_size, context_len, d_model, num_layers, num_heads, d_ff, ): super ().__init__() self .embedding = Embedding(vocab_size, d_model) self .layers = nn.ModuleList([ TransformerBlock( d_model, num_heads, d_ff, context_len, ) for _ in range (num_layers) ]) self .norm = RMSNorm(d_model) self .lm_head = Linear(d_model, vocab_size) def forward (self, tokens ): B, T = tokens.shape positions = torch.arange(T, device=tokens.device) positions = positions.unsqueeze(0 ).expand(B, T) x = self .embedding(tokens) for layer in self .layers: x = layer(x, positions) x = self .norm(x) return self .lm_head(x)
cs336_assignment_1中尚未学习的有:Adam优化器、余弦退火学习率、梯度裁剪、checkpoint.RoPE也还没学会