
scaling laws
导入
我们知道,像H100,A100这样的高性能GPU在训练大规模深度学习模型时成本是很昂贵的,因此,我们不能盲目地设定参数来试错,而是需要有一定的理论依据来指导我们如何选择模型的规模和训练数据的规模。Scaling Laws(缩放定律)为我们提供了这样的理论依据。
训练一个大模型需要
- 基础设施
- 数据
- 训练策略
虽然你有算力(H100)、有系统(Infra)、有数据(Dataset),但当你真正要敲下回车键开始训练时,你会面临一系列决策瘫痪:
- 我应该训练一个 600 亿参数的模型,跑久一点?
- 还是训练一个 1750 亿参数的模型,跑短一点?
- 层数要多深?宽度要多大?
设计大模型有无数种参数组合,盲目尝试太贵,照抄别人又不一定对。
利用缩放定律。我们发现模型的性能(Loss)与资源(算力、参数)在双对数坐标下呈线性关系。
通过学习 Scaling Laws,我们可以更好地理解如何在给定的计算预算下,选择模型规模和训练数据规模,以达到最佳的性能表现。
scaling laws 历史和背景
- 在经典的统计学习理论(如 VC 维理论)中,理论学家早就推导出模型的估计误差 $\epsilon$ 会随着样本量 $n$ 的增加而衰减,通常表现为 $n^{-\alpha}$ 或 $1/\sqrt{n}$ 的形式
- 1993年:发现误差随数据增加而有规律地下降(幂律初现)。
- 2001年:发现数据量的作用可能大于算法的精巧设计(数据为王)。
- 2012年:在复杂任务(如翻译)上验证并确定了幂律是描述这种增长的最佳数学模型。
- 2017年:深度学习时代的里程碑 (Hestness et al.)
- 这是现代大模型缩放研究的开山之作,涵盖了机器翻译、语言模型和语音识别等多个领域 。
- 三阶段模型:它提出了模型性能随数据增长的三个阶段 :
- 小数据区(Small Data Region):误差平稳,类似瞎猜。
- 幂律区(Power-law Region):误差随数据指数级下降,这是我们关注的重点区域。
- 不可约误差区(Irreducible Error Region):误差趋于平缓,达到数据本身的极限。

Hestness (2017) 的研究还留下了几个极其重要的预言:
- 涌现(Emergence):在小数据量下,模型可能表现极差(Accuracy Cliffs),但这不代表模型不行,可能只是还没进入“幂律区”。研究人员需要小心,不要因为小规模测试失败就过早否定一个模型 。
- 算力预测:利用缩放曲线,可以推算出为了达到特定精度需要多少算力,从而指导硬件规划 。
- 速度即精度(Speed = Accuracy):如果某种技术(如低精度计算)能提高计算速度,即便单次精度略有下降,只要能利用省下的时间跑更多数据,最终效果可能反而更好 。
这为后来大模型时代坚信“Scaling Laws”提供了坚实的实证基础
缩放定律并非玄学,它是统计学习理论在深度学习时代的验证。从 90 年代起,研究人员就发现误差随数据量呈幂律下降,并最终在 2017 年确立了以“幂律区”为核心的现代深度学习扩展模型。
具体缩放行为
学完这一部分你应该对以下问题有所了解:
- 数据如何影响模型性能?
- 数据和模型大小怎么权衡?
- 超参数在大模型上该怎么设?

上图可以看出,模型的损失(Loss)与计算量(C),训练数据量(N)和模型参数量(P)之间都存在幂律关系。

甚至在不同质量的数据集上,这种幂律关系依然成立,并且表现出类似的斜率。这说明不同质量的数据集只会影响幂律的截距,而不会改变其斜率。
数据量大小对模型性能的影响

上图展示了不同数据量对损失的影响。可以看出,这符合Hestness等人在2017年提出的三阶段模型中的幂律区。
我们很容易理解,数据量越大,模型的表现越好,因为更多的数据提供了更多的信息,帮助模型更好地学习数据的分布。但是为什么呈现的是幂律关系呢?这可以从统计学习理论中找到解释。
最简单的统计任务:
假设我们有一个非常简单的任务:估计一组数据的平均值(Mean)。
输入是 $n$ 个数据点 $x_1…x_n$,它们服从正态分布。
你的任务是计算 $\hat{\mu} = \frac{\Sigma x_i}{n}$ 。
- 误差公式:根据经典的统计学原理,估计的均方误差(Squared Error)是 $E[(\hat{\mu} - \mu)^2] = \frac{\sigma^2}{n}$ 。
- 这是一个非常标准的结论:样本量 $n$ 越大,误差越小。
- 这就是一个缩放定律:如果我们在双对数坐标下写出这个公式,它就是 $\log(Error) = -\log n + 2 \log \sigma$ 。这意味着误差不仅随着数据量下降,而且遵循多项式速率(Polynomial Rate) $1/n^{\alpha}$(在这个例子里 $\alpha=1$)。
那么这个时候我们就有了新问题,基于上面的经典理论(如线性回归),我们预期的误差下降速度应该是 $1/n$(即斜率为 -1,或者说 $y = -x + C$),那为什么实际上,机器翻译 (左图):斜率大约是 $\alpha = 0.36$ 或 $0.13$ 。语音识别 (中图):斜率大约是 $\alpha = 0.30$ 。语言模型 (右图):这是最夸张的,斜率只有 $\alpha = 0.095$

(Bahri 2021)提出:缩放定律的斜率,反映了数据的“内在维度”。
虽然图片、文本等数据看起来是高维的(比如一张图有 $1024 \times 1024$ 像素),但它们实际上分布在一个低维的流形上(Intrinsic Dimension)。
缩放定律中的指数 $\alpha$ 与这个内在维度 $d$ 有关,近似满足 $\alpha \approx 4/d$(或者类似的反比关系)。
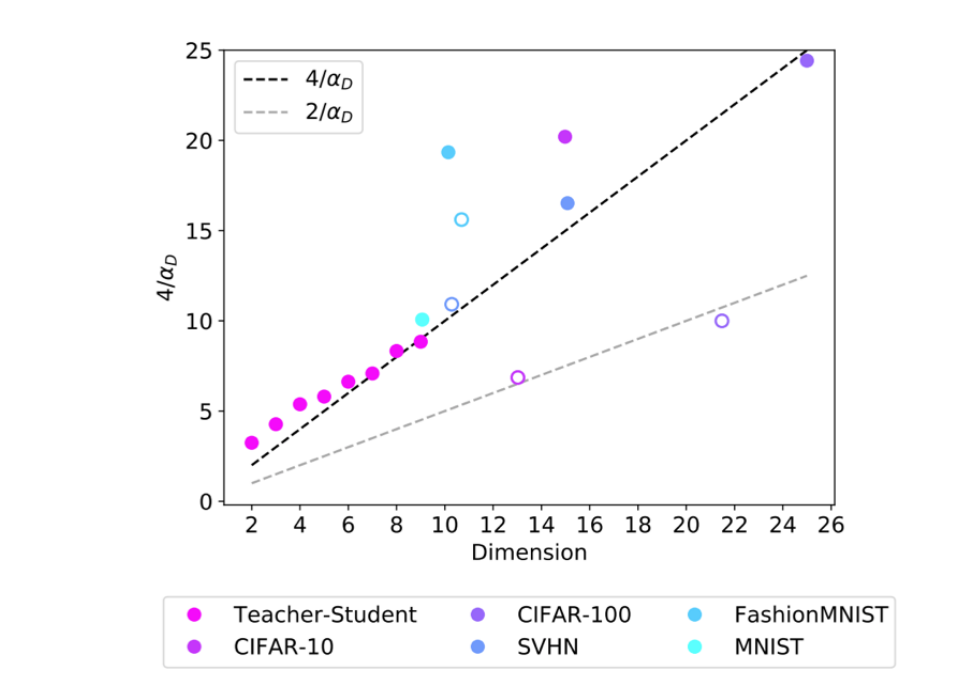
还记得语言模型的 $\alpha \approx 0.095$ 吗?这是一个非常小的数字。根据这个理论,这意味着人类语言数据的内在维度非常高。语言包含了极其复杂的语法、逻辑、知识和上下文关联,因此我们需要极其庞大(万亿级 Token)的数据才能“填满”这个高维空间,让模型学会。
数据质量与构成对模型性能的影响
们在实际训练大模型时必须面对的三个核心数据决策问题:
- 最佳配比 (Picking optimal data mixture):
如果你有代码数据、维基百科、网页数据,应该按什么比例混合?我们能不能用便宜的小模型试出这个比例,然后应用到大模型上? - 数据重复 (Repeating data):
高质量数据(如教科书)是有限的。如果数据不够了,我是应该把好数据重复训练几遍(Epochs > 1),还是去硬凑一些烂数据? - 质量与数量的平衡 (Balancing quality with repetition):
这是前两者的结合。是“少而精(重复读)”好,还是“多而杂(只读一遍)”好?
我们先前提到过,数据质量的好坏,只会改变缩放曲线的截距(上下位置),而不会改变斜率,这意味着无论你用高质量的维基百科,还是低质量的网页爬虫,随着模型变大,性能提升的速率是一样的(斜率相同)。但是,高质量数据能让你赢在起跑线上(曲线整体向下平移,Loss 更低)。

上图的 U 型曲线 “Expected error intercept” 展示了数据混合比例对性能的影响。
解读:如果数据来源太单一(比例 $q$ 接近 0 或 1),误差截距(Error Intercept)会变高。只有当多种数据源混合得当(在中间的低谷区)时,模型的起始性能才是最好的。这强调了收集多样化数据 (Diverse Data) 的重要性 。
数据有限,需要重复利用
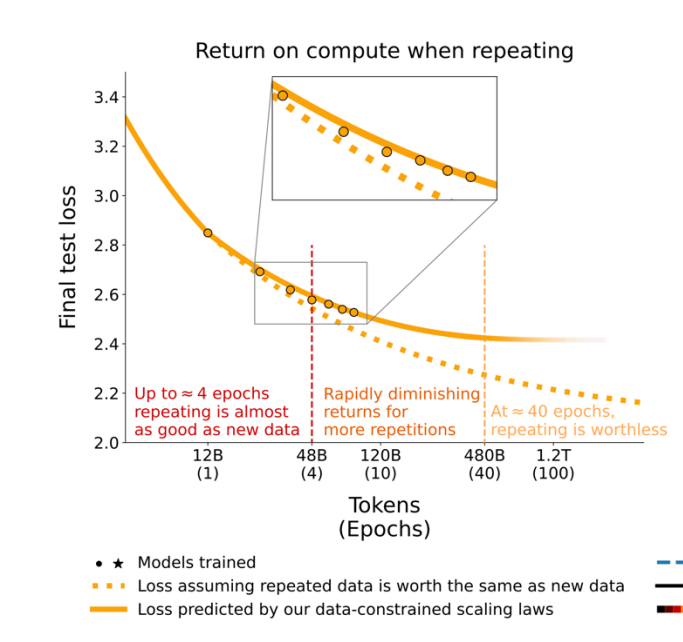
如图,4个epoch的重复训练,数据几乎和新数据一样好,但是超过4个epoch后,收益递减,到40个epoch时,数据的收益已经接近0了。
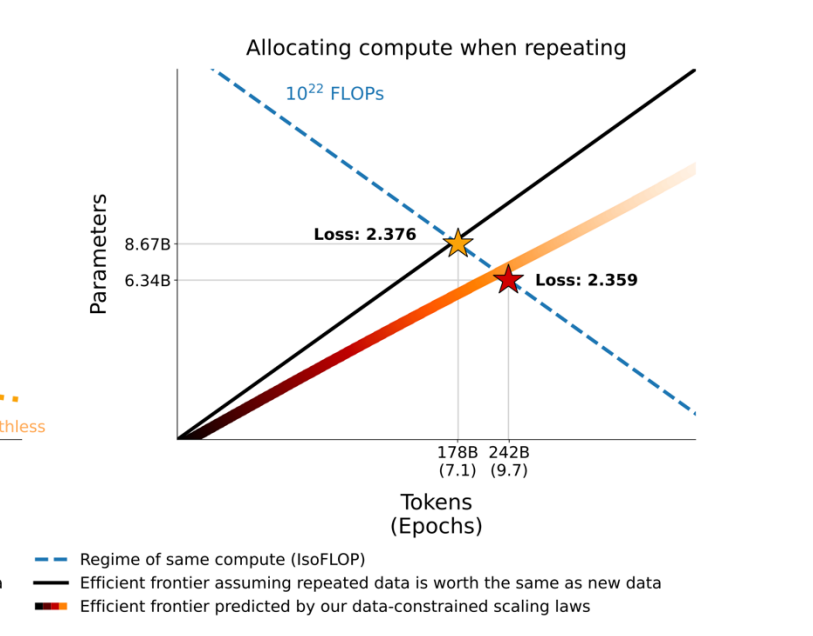
但是如果你不得不使用重复的数据,那么在固定算力下,你应该去尝试使用参数量更大的模型,来最大化利用重复数据的价值。
既然重复数据有坏处,那我们在构建数据集时应该怎么选?是“只用高质量数据但多重复几遍”,还是“混入低质量数据但保持新鲜”?
- 小算力 (Small Compute):挑食(Highly aggressive filtering)。
因为你训练步数少,高质量数据(E)即使重复几次还没到收益递减点。所以只用最好的数据 E,多跑几遍,效果最好。 - 中算力 (Medium Compute):适度。
数据 E 重复次数太多了,开始亏了。这时候引入次好的数据 D(E+D),虽然质量低了点,但胜在是“新”的。 - 大算力 (Large Compute):不挑食(Less aggressive filtering)。
你需要海量数据。如果只用 E 和 D,重复次数会高到让 Loss 无法下降。这时候,混入更低质量的 C(E+D+C)反而效果更好,因为数据的新鲜度(Unique Tokens)战胜了数据质量的噪音。
总结:数据扩展定律 (Recap: data scaling laws)
强调了四个核心结论:
- 惊人的线性关系 (Remarkably linear relationship):
再次确认核心发现:在双对数坐标系(Log-Log Plot)下,数据量(Log-Data)和 错误率(Log-Error)呈现几乎完美的直线关系。这就是所谓的“幂律”。 - 普适性 (Holds across domains):
这个规律不偏科。无论是文本(LLM)、图像(Vision)、还是音频,只要是深度学习模型,都遵循这个规律。 - 理论理解 (Theory understanding):
回顾了刚才那个“均值估计(Mean Estimation)”的玩具例子。
核心意思是:缩放定律不是黑魔法,它在数学上类似于统计学中的泛化界(Generalization Bounds),即随着样本增多,估计误差会自然衰减。 - 应用 (Applications):
我们在工程上怎么用它?用来指导数据收集(Data Collection)和数据清洗/筛选(Curation)。比如决定是用少量高质量数据,还是海量低质量数据。
参数量(模型大小)对模型性能的影响
在训练大模型之前,你需要敲定以下四个核心超参数:
- 架构 (Architecture):用什么类型的神经网络?(Transformer)。
- 优化器 (Optimizer):用什么算法更新参数?(Adam 及其参数设置)。
- 长宽比/深度 (Aspect ratio / depth):
这是一个非常经典的问题:“宽而浅”好,还是“窄而深”好?
比如同样是 10 亿参数,你是做 100 层每层 1000 维,还是做 10 层每层 10000 维?
Kaplan 的论文会告诉你,只要总参数量一样,形状其实没那么重要(Shape doesn’t matter much)。
另外,一层模型性能要显著低于多层模型,但是多层模型之间并没有太大变化。 - 批次大小 (Batch size):
训练时一次喂给模型多少数据?这里会涉及到 “临界批次大小(Critical Batch Size)” 的概念。
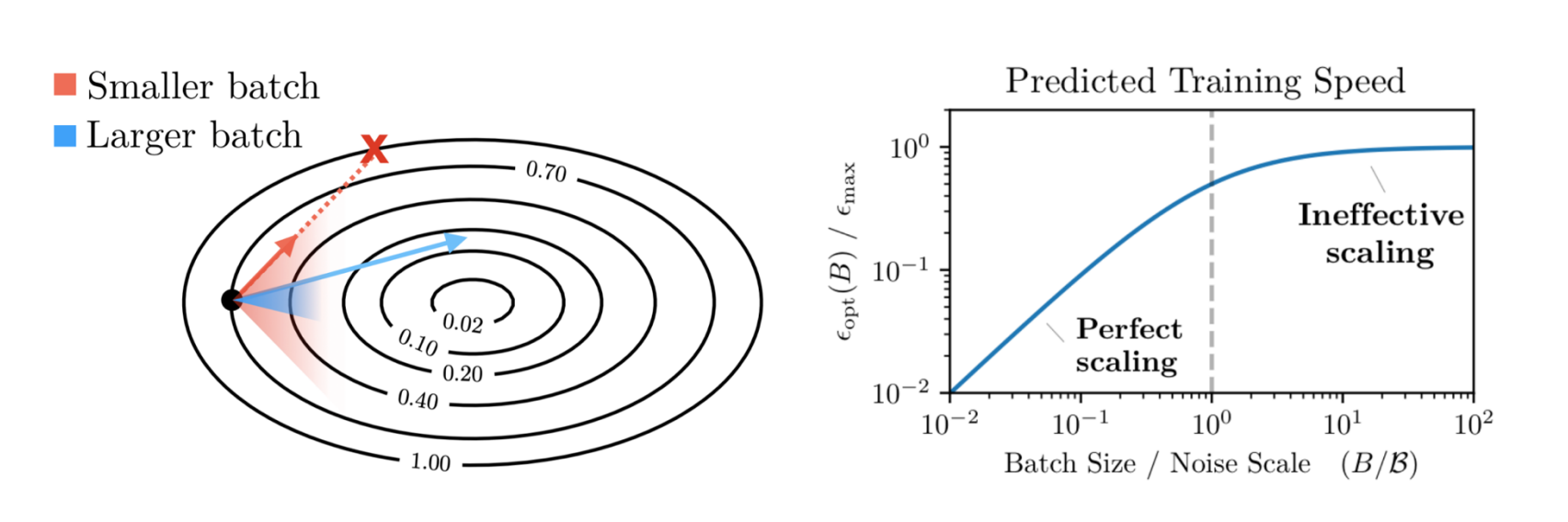
左侧等高线图: 展示了梯度下降的路径。
- 较小 Batch (Red): 梯度估计噪声大,路径曲折,需要更多迭代步数才能到达中心。
- 较大 Batch (Blue): 梯度估计更精确,路径更直,迭代步数更少。
右侧训练速度曲线: 展示了“边际收益递减”规律。 - 完美缩放区 (Perfect Scaling): 当 Batch Size 远小于 $B_{crit}$ 时,增加一倍 Batch Size,训练步数就能减少一半,总计算量几乎不变。
- 无效缩放区 (Ineffective Scaling): 当 Batch Size 超过 $B_{crit}$ 后,继续增大 Batch Size 对减少训练步数的贡献微乎其微,导致大量计算资源浪费。
核心定义: $B_{crit}$ 是这两者之间的平衡点,即在不显著浪费计算量的前提下,能实现最大并行化的 Batch Size。
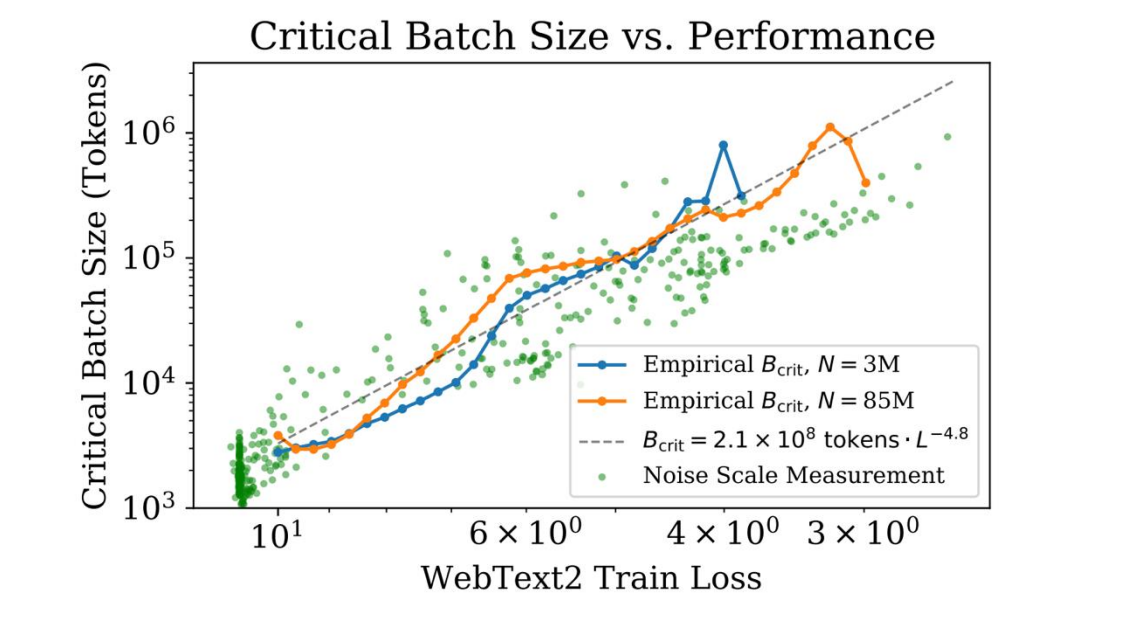
目标 Loss 越小,需要的 Batch Size 越大。 这意味着在训练的后期,或者当你试图训练一个更强大的模型时,你可以使用更大的 Batch Size 来维持并行效率。
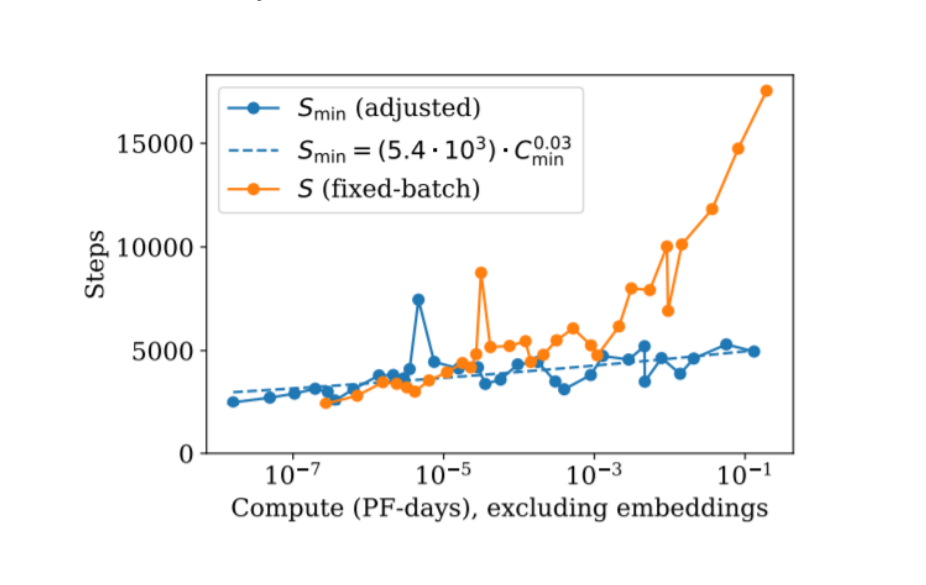
当我们增加计算量和模型大小时,应该如何调整训练策略?
两种策略对比:
- 固定 Batch,增加步数 (Orange): 随着计算量(Compute)增加,步数急剧上升。这会导致训练时间变长,难以通过增加机器来加速。
- 增大 Batch,维持步数 (Blue): 图中蓝线($S_{min}$)显示,如果根据缩放法则调整 Batch Size,即使计算量增加几个数量级,所需的训练步数增长也非常缓慢($S \propto C^{0.03}$)。
- 对数据并行的启示: 这是一个巨大的好消息!它意味着随着模型规模扩大,我们可以通过增加数据并行度(更大的 Batch Size)来消耗增加的计算量,而不需要无限期地延长训练天数。这使得大规模分布式训练在工程上是可行的。
学习率调整:
实施 $\mu P$ 主要包含三个步骤: 参数分组、初始化调整、学习率缩放 。
核心思想是:设定一个较小的 基准模型(Base Model) (例如宽度 128),在这个模型上调好超参数,然后应用以下规则将参数迁移到 目标大模型(Target Model) (例如宽度 2048)。
假设你的模型宽度($d_{model}$)从基准模型的 $M$ 扩大到了 $M’ = r \times M$,即放大倍数为 $r$。具体的实施清单如下:
- 第一步:参数分类 (Parameter Grouping)
在代码中,你需要将模型的所有参数分为三类,因为它们适用不同的缩放规则:
- Matrix-like(矩阵类): 输入和输出维度都会随着模型宽度变大而变大的张量。
- 例如: Transformer 内部的 QKV 投影层、FFN 的全连接层权重。
- 特征: 形状通常是 $[d_{model}, d_{model}]$ 或 $[d_{model}, 4d_{model}]$。
- Others(向量/嵌入类): 只有一个维度或没有维度随宽度变化的张量。
- 例如: Embedding 层 (词表大小固定,只有嵌入维度变)、LayerNorm 的 scale/bias、所有的 Bias 项。
- 引用图表: “Note that embedding layers are ‘others’.”
- Output(输出层): 特指将隐藏层映射回词表的那一层(LM Head)。
- 特征: 形状是 $[d_{model}, VocabSize]$。
- 第二步:调整初始化 (Initialization)
你需要重写参数的初始化逻辑,或者在标准初始化后手动缩放。
- Matrix-like 权重:
- 方差(Variance)需要除以 $r$,即标准差(Std)需要除以 $\sqrt{r}$。
- 目的: 保持激活值在前向传播中的数值稳定性,防止随着宽度增加激活值爆炸。
- Others & Output 权重:
- 保持标准的初始化方差不变(例如常用的 Xavier 或 Kaiming 初始化)。
- 第三步:调整学习率 (Learning Rate Scaling)
这是 $\mu P$ 最关键的一步。在定义优化器(Optimizer)时,不能给所有参数同一个学习率,必须使用 Parameter Groups 。
- Matrix-like 权重:
- 学习率设置为 $\text{BaseLR} / r$。
- 解释: 宽层包含更多参数,梯度的累加值会更大,因此需要更小的步长来抵消。
- Others & Output 权重:
- 学习率保持为 $\text{BaseLR}$(不变)。
- 解释: 这些参数的梯度规模不会随宽度剧烈变化,因此沿用基准学习率。
BaseLR指的是在小模型中探索出的最佳学习率。
- 第四步:输出层乘子 (Output Multiplier)
图表中提到 “Multiplier (output) $\to \tau/r$”。这通常有两种实现方式:
- 显式乘法: 在计算 Logits 之前,将输出层的输出乘以一个标量 $1/r$。
$$
\text{Logits} = \frac{1}{r} \times (W_{out} \cdot h)
$$ - 初始化缩放: 或者将输出层权重的初始化方差进一步缩小。
到底该把钱花在哪?(Kaplan vs. Chinchilla)
这是这节课最核心、也是最容易晕的地方。假设老板给你一笔固定的预算(即固定的计算量 Compute, $C$),你应该造一个“参数巨大的模型但少训练一点数据”,还是造一个“参数适中但多训练一点数据”的模型?这经历了两个阶段的认知迭代:
阶段1:
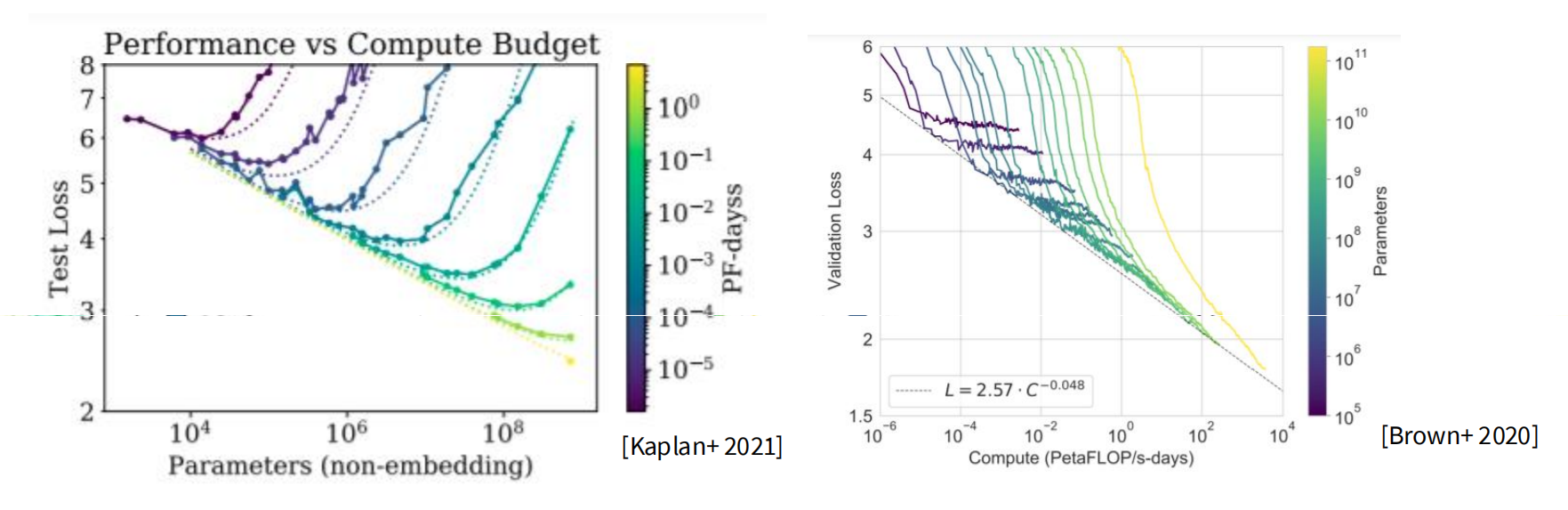
核心结论:大模型更“省钱”?
这张图主要引用了 OpenAI 的 Kaplan et al. 2020 的结论。他们的发现有些反直觉:
- 大模型其实是样本效率(Sample Efficiency)更高的。
- 与其用很多的数据去把一个小模型训练到收敛, 不如用较少的数据去训练一个非常大的模型(即使不训练到收敛) ,后者通常能达到更低的 Loss,而且消耗的总算力可能还更少。
- 这就是为什么当时的趋势是 “Train Large, Stop Early” (练个大的,早点停)。
阶段2:
- 反转 :DeepMind 发现 Kaplan 的实验方法有点问题,导致高估了参数的作用。他们提出了 Chinchilla定律。
- 结论 :参数量和数据量应该等比例扩大。
- 建议比例 :计算量增加 10 倍,参数量和数据量应该各增加约 3.16 倍 ($\sqrt{10}$),即系数各为 0.5 左右。
- 核心公式 :在给定算力预算下,最优模型大小 $N_{opt}$ 和最优数据量 $D_{opt}$ 的关系是线性同步增长的。
- 产物 : Chinchilla (70B)。虽然它的参数只有 GPT-3 的不到一半,但因为使用了 4 倍于 GPT-3 的数据量,它的性能反而更好 。