
深度学习初识
反向传播
我们将考虑一个通用输入 $x$,并计算 $h_\theta(x)$ 关于 $\theta$ 的梯度。为简便起见,我们用 $o$ 作为 $h_\theta(x)$ 的简写($o$ 代表 output,即输出)。为简便起见,虽然有滥用符号之嫌,我们使用 $J = \frac{1}{2} (y - o)^2$ 来表示损失函数。(注意:这覆盖了 7.1 节中将 $J$ 定义为总损失的设定。)我们的目标是计算 $J$ 关于参数 $\theta$ 的导数。
单个神经元的反向传播
先假设$x$和$w$都是简单的标量。我们有如下:
$x \xrightarrow{w, b} z \rightarrow o \rightarrow J$
前向公式:
$z = w \cdot x + b$
$o = \text{ReLU}(z)$
$J = \frac{1}{2}(y - o)^2$
求导 (链式法则):
由链式法则可得:
其中:
因此:
向量化:
1 | graph LR |
实际应用中,输入通常是一个特征向量 $\vec{x}$。
维度定义:$\vec{x} = [x_1, x_2, x_3, x_4]^T$ (4维列向量)$\vec{w} = [w_1, w_2, w_3, w_4]^T$ (4维列向量)前向公式:$$z = \vec{w}^T \vec{x} + b \quad (\text{结果是标量})$$
梯度结果:$\frac{\partial J}{\partial \vec{w}}$ 的结果必须和 $\vec{w}$ 的形状一致(也是 4维列向量)。$$ \frac{\partial J}{\partial \vec{w}} = \underbrace{(o - y) \cdot \text{ReLU}'(z)}{\text{标量系数}} \cdot \underbrace{\vec{x}}{\text{向量}}$$
两层神经网络
现在考虑一个两层神经网络:
$w^{[2]}$表示这是第二层的权重,$w^{[1]}j$表示第一层中第$j$个神经元的权重。
我们将使用 $(w^{[2]})\ell$ 来表示向量 $w^{[2]}$ 的第 $\ell$ 个坐标分量,用 $(w^{[1]}j)\ell$ 来表示向量 $w^{[1]}_j$ 的第 $\ell$ 个坐标分量。
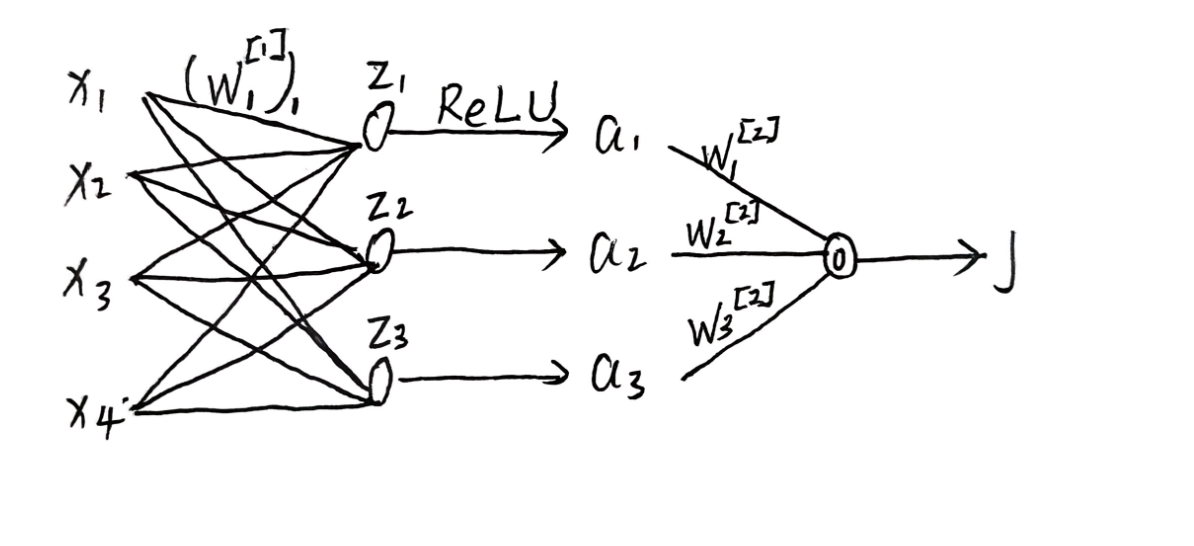
假设有m个隐藏神经元
对于所有的 $j \in [1, …, m]$:$$z_j = (w^{[1]}_j)^T x + b^{[1]}_j \quad \text{其中 } w^{[1]}_j \in \mathbb{R}^d, b^{[1]}_j \in \mathbb{R}$$$$a_j = \text{ReLU}(z_j), \quad a = [a_1, …, a_m]^T \in \mathbb{R}^m$$$$o = (w^{[2]})^T a + b^{[2]} \quad \text{其中 } w^{[2]} \in \mathbb{R}^m, b^{[2]} \in \mathbb{R}$$$$J = \frac{1}{2} (y - o)^2 $$
通过调用链式法则,以 $J$ 为输出变量,$o$ 为中间变量,$(w^{[2]})\ell$ 为输入变量,我们有:$$\frac{\partial J}{\partial (w^{[2]})\ell} = \frac{\partial J}{\partial o} \frac{\partial o}{\partial (w^{[2]})\ell} = (o - y) \frac{\partial o}{\partial (w^{[2]})\ell} = (o - y) a_\ell$$
计算 $\frac{\partial J}{\partial (w^{[1]}j)\ell}$ 则更有挑战性。为了计算它,我们首先调用链式法则,以 $J$ 为输出变量,$z_j$ 为中间变量,$(w^{[1]}j)\ell$ 为输入变量:$$\frac{\partial J}{\partial (w^{[1]}j)\ell} = \frac{\partial J}{\partial z_j} \cdot \frac{\partial z_j}{\partial (w^{[1]}j)\ell} = \frac{\partial J}{\partial z_j} \cdot x_\ell$$(因为 $\frac{\partial z_j}{\partial (w^{[1]}j)\ell} = x_\ell$。)因此,只需计算 $\frac{\partial J}{\partial z_j}$ 即可。我们再次调用链式法则,以 $J$ 为输出变量,$a_j$ 为中间变量,$z_j$ 为输入变量:$$\frac{\partial J}{\partial z_j} = \frac{\partial J}{\partial a_j} \frac{\partial a_j}{\partial z_j} = \frac{\partial J}{\partial a_j} \text{ReLU}'(z_j)$$现在只需计算 $\frac{\partial J}{\partial a_j}$,我们再次调用链式法则,以 $J$ 为输出变量,$o$ 为中间变量,$a_j$ 为输入变量:$$\frac{\partial J}{\partial a_j} = \frac{\partial J}{\partial o} \frac{\partial o}{\partial a_j} = (o - y) \cdot (w^{[2]})_j$$现在结合上面的方程,我们得到:$$\frac{\partial J}{\partial (w^{[1]}j)\ell} = (o - y) \cdot (w^{[2]})j \cdot \text{ReLU}'(z_j) \cdot x\ell$$
算法 :双层神经网络的反向传播前向传播:
- 按照神经网络的定义,计算 $z_1, …, z_m, a_1, …, a_m$ 和 $o$ 的值。
- 计算输出层梯度:计算 $\frac{\partial J}{\partial o} = (o - y)$。
- 计算隐藏层梯度(反向传播核心):对于 $j = 1, …, m$,通过以下公式计算 $\frac{\partial J}{\partial z_j}$:$$\frac{\partial J}{\partial z_j} = \frac{\partial J}{\partial o} \frac{\partial o}{\partial a_j} \frac{\partial a_j}{\partial z_j} = \frac{\partial J}{\partial o} \cdot (w^{[2]})_j \cdot \text{ReLU}'(z_j) $$
- 计算参数梯度:通过以下公式计算 $\frac{\partial J}{\partial (w^{[1]}j)\ell}, \frac{\partial J}{\partial b^{[1]}_j}, \frac{\partial J}{\partial (w^{[2]})j}, \frac{\partial J}{\partial b^{[2]}}$:$$\frac{\partial J}{\partial (w^{[1]}j)\ell} = \frac{\partial J}{\partial z_j} \cdot \frac{\partial z_j}{\partial (w^{[1]}j)\ell} = \frac{\partial J}{\partial z_j} \cdot x\ell$$$$\frac{\partial J}{\partial b^{[1]}_j} = \frac{\partial J}{\partial z_j} \cdot \frac{\partial z_j}{\partial b^{[1]}_j} = \frac{\partial J}{\partial z_j}$$$$\frac{\partial J}{\partial (w^{[2]})_j} = \frac{\partial J}{\partial o} \frac{\partial o}{\partial (w^{[2]})_j} = \frac{\partial J}{\partial o} \cdot a_j$$$$\frac{\partial J}{\partial b^{[2]}} = \frac{\partial J}{\partial o} \frac{\partial o}{\partial b^{[2]}} = \frac{\partial J}{\partial o}$$
- 为什么原来的复杂度是 $O(N^2)$?
文中的 $N$(或 $p$)指的是网络中参数的总数(权重 $w$ 和偏置 $b$ 的总和)。假设你的网络有 $N=1000$ 个参数。你想知道每一个参数对最终 Loss ($J$) 的影响(即求 1000 个导数)。
朴素做法(Naive Approach):如果你不懂链式法则的“反向”传递,你只能针对每一个参数,单独跑一遍“影响链路”。逻辑:想求参数 $w_1$ 的导数:你需要算出从 $w_1$ 到 $z$ 到 $o$ 再到 $J$ 的整条链路。这需要遍历网络的一部分,耗时约为 $O(N)$。想求参数 $w_2$ 的导数:你重新算出从 $w_2$ 到 $z$ 到 $o$ 再到 $J$ 的整条链路。耗时又是 $O(N)$。…想求参数 $w_{1000}$ 的导数:你再次重新算一遍。耗时 $O(N)$。总账:$$\text{总时间} = \text{参数个数} \times \text{每次计算单条链路的时间} = N \times O(N) = O(N^2)$$致命弱点:你会发现,从隐藏层 $z$ 到输出 $J$ 的这一段路(即 $\frac{\partial J}{\partial z}$),被重复计算了 1000 次!这就是巨大的浪费。 - 它是怎么降低到 $O(N)$ 的?(聪明办法:共享计算)反向传播(Backpropagation)的核心发现是:所有的参数都共享同一个“后半段链路”。根据文中提到的公式:$$\frac{\partial J}{\partial (w^{[1]}j)\ell} = \underbrace{\frac{\partial J}{\partial z_j}}{\text{共享项}} \cdot \underbrace{\frac{\partial z_j}{\partial (w^{[1]}j)\ell}}{\text{独有项}}$$第一步(一次性计算共享项):我们先算好“总误差 $J$ 对隐藏层 $z_j$ 的导数”(即 $\delta_j = \frac{\partial J}{\partial z_j}$)。这一步只需要从 $J$ 往回走到 $z$,遍历一次网络。耗时:$O(N)$。关键点:算完后,把这个结果存起来(Cache)。第二步(分发):现在要算那 1000 个参数的导数。对于 $w_1$:直接拿存好的 $\delta$ 乘以 $w_1$ 对应的输入 $x_1$。这是一次乘法,$O(1)$。对于 $w_2$:直接拿存好的 $\delta$ 乘以 $w_2$ 对应的输入 $x_2$。这是一次乘法,$O(1)$。…对于 $w_{1000}$:一次乘法,$O(1)$。总账:$$\text{总时间} = \text{计算共享项的时间(反向一次)} + \text{所有参数做乘法的时间}$$$$= O(N) + (N \times O(1)) = O(N)$$
带有向量化的两层神经网络
扩展到多层神经网络
算法 :多层神经网络的反向传播
- 前向传播:
对于 $k = 1, \dots, r-1$,计算并存储 $a^{[k]}$ 和 $z^{[k]}$ 的值,以及 $J$。这通常被称为“前向传播”(forward pass)。 - 计算输出层误差:计算 $\delta^{[r]} = \frac{\partial J}{\partial z^{[r]}} = (z^{[r]} - o)$。(注:原文此处 $o$ 应指 $y$ 或目标值,根据上下文,$z^{[r]}$ 即为输出)。
- 反向循环:对于 $k = r-1$ 到 $1$ 做:
- 计算隐藏层误差:$$\delta^{[k]} = \frac{\partial J}{\partial z^{[k]}} = (W^{[k+1]T}\delta^{[k+1]}) \odot \text{ReLU}'(z^{[k]})$$
- 计算梯度:$$\frac{\partial J}{\partial W^{[k+1]}} = \delta^{[k+1]}a^{[k]T}$$$$\frac{\partial J}{\partial b^{[k+1]}} = \delta^{[k+1]}$$