
分类问题
二元分类
$y$只有0,1两种取值。
例如,如果我们尝试建立一个电子邮件垃圾邮件分类器,那么 $x^{(i)}$ 可能是邮件的一些特征,$y$ 如果是垃圾邮件则为 1,否则为 0。0 也被称为 负类(negative class) ,1 被称为 正类(positive class) ,它们有时也用符号 “-” 和 “+” 表示。给定 $x^{(i)}$,相应的 $y^{(i)}$ 也被称为训练样本的 标签(label) 。
逻辑回归 (Logistic Regression)
假设函数$h_\theta(x)$
$$
h_\theta(x) = g(\theta^T x) = \frac{1}{1 + e^{-\theta^T x}}
$$
其中
$$
g(z) = \frac{1}{1 + e^{-z}}
$$
被称为逻辑函数(logistic function)或 Sigmoid 函数。
Sigmoid 函数具有如下性质:当 $z \to \infty$ 时,$g(z) \to 1$;当 $z \to -\infty$ 时,$g(z) \to 0$。因此 $h(x)$ 始终被限制在 0 和 1 之间。
梯度上升法
我们假设:
$$
P(y=1 | x; \theta) = h_\theta(x)
$$
$$
P(y=0 | x; \theta) = 1 - h_\theta(x)
$$
合二为一
$$
p(y | x; \theta) = (h_\theta(x))^y (1 - h_\theta(x))^{1-y}
$$
当我们拥有 $n$ 个独立同分布(IID)的训练样本时,我们要计算观察到这一组数据的总概率。有了这个统一公式,似然函数 $L(\theta)$ 就可以简单地写成所有样本概率的乘积:
$$
L(\theta) = \prod_{i=1}^n p(y^{(i)} | x^{(i)}; \theta) = \prod_{i=1}^n (h_\theta(x^{(i)}))^{y^{(i)}} (1 - h_\theta(x^{(i)}))^{1-y^{(i)}}
$$
利用对数似然函数 $\ell(\theta)$ 并对其求导,
$$
\ell(\theta) = \log L(\theta) = \sum_{i=1}^n \left[ y^{(i)} \log h_\theta(x^{(i)}) + (1 - y^{(i)}) \log (1 - h_\theta(x^{(i)})) \right]
$$
$$
\frac{\partial}{\partial \theta_j} \ell(\theta) = \left( \frac{y}{g(\theta^T x)} - \frac{1-y}{1 - g(\theta^T x)} \right) \cdot \frac{\partial}{\partial \theta_j} g(\theta^T x)
$$
$$
h_\theta(x) = g(\theta^T x)
$$
因为$g’(z) = g(z)(1-g(z))$
所以可求得
$$
\frac{\partial}{\partial \theta_j} g(\theta^T x) = g(\theta^T x)(1 - g(\theta^T x)) \cdot \frac{\partial}{\partial \theta_j} (\theta^T x)
$$
由于 $\theta^T x = \theta_0 x_0 + \theta_1 x_1 + \dots + \theta_j x_j + \dots$,所以 $\frac{\partial}{\partial \theta_j} (\theta^T x) = x_j$
将上述性质带入公式中:
$$
\frac{\partial}{\partial \theta_j} \ell(\theta) = \left( \frac{y}{g(\theta^T x)} - \frac{1-y}{1 - g(\theta^T x)} \right) \cdot g(\theta^T x)(1 - g(\theta^T x)) \cdot x_j
$$
现在将 $g(\theta^T x)(1 - g(\theta^T x))$ 乘入括号内:
- 第一项: $\frac{y}{g(\theta^T x)} \cdot g(\theta^T x)(1 - g(\theta^T x)) = y(1 - g(\theta^T x))$
- 第二项: $\frac{1-y}{1 - g(\theta^T x)} \cdot g(\theta^T x)(1 - g(\theta^T x)) = (1 - y)g(\theta^T x)$
公式变为:
$$
= \left[ y(1 - g(\theta^T x)) - (1 - y)g(\theta^T x) \right] x_j
$$
展开括号:
$$
= \left[ y - y \cdot g(\theta^T x) - g(\theta^T x) + y \cdot g(\theta^T x) \right] x_j
$$
注意中间的 $y \cdot g(\theta^T x)$ 项互相抵消了,剩下:
$$
= (y - g(\theta^T x)) x_j
$$
因为 $h_\theta(x) = g(\theta^T x)$,所以最终结果为:
$$
\frac{\partial}{\partial \theta_j} \ell(\theta) = (y - h_\theta(x)) x_j
$$
我们得到更新规则(梯度上升,因为这个是要最大化似然函数):
$$
\theta_j := \theta_j + \alpha(y^{(i)} - h_\theta(x^{(i)})) x_j^{(i)}
$$
虽然这个形式与线性回归的 LMS 规则完全一样,但它是一个不同的算法,因为这里的 $h_\theta(x)$ 是非线性的。
感知器学习算法 (Perceptron Learning Algorithm)
如果我们强迫 $g(z)$ 输出精确的 0 或 1,即使用阈值函数:
当 $z \ge 0$ 时 $g(z)=1$,当 $z < 0$ 时 $g(z)=0$。
使用同样的更新规则,我们就得到了感知器算法。它在历史上被认为是神经元的粗糙模型,但它不像逻辑回归那样具有明确的概率解释。
牛顿法 (Newton’s Method)
假设我们有一个函数 $f : \mathbb{R} \to \mathbb{R}$,希望找到一个 $\theta$ 值使得 $f(\theta) = 0$。这里 $\theta \in \mathbb{R}$ 是一个实数
牛顿法执行如下更新:
$$
\theta := \theta - \frac{f(\theta)}{f’(\theta)}
$$
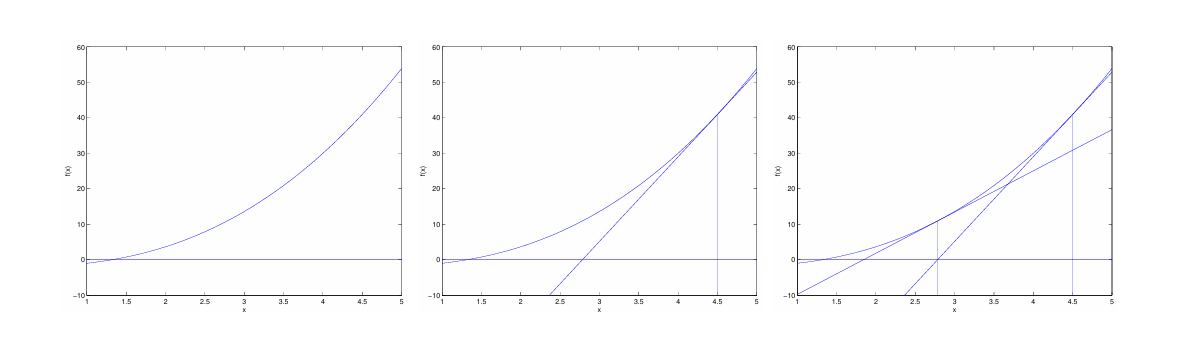
以下是牛顿法运行过程的图示:
在左图中,我们看到了函数 $f$ 以及直线 $y=0$。我们试图找到使 $f(\theta) = 0$ 的 $\theta$;实现这一目标的 $\theta$ 值约为 1.3。假设我们以 $\theta = 4.5$ 初始化算法。牛顿法随后在 $\theta = 4.5$ 处拟合一条与 $f$ 相切的直线,并解出该直线为 0 的位置(中图)。这给出了我们的下一个猜测值 $\theta \approx 2.8$。右图显示了再运行一次迭代的结果,将 $\theta$ 更新为约 1.8。经过几次迭代后,我们迅速接近 $\theta = 1.3$。
而对于我们现在的逻辑回归问题就是要寻找似然函数的一阶导数为0的$\theta$,
通过令 $f(\theta) = \ell’(\theta)$,我们可以使用同样的算法来极大化 $\ell$,从而得到更新规则:
$$
\theta := \theta - \frac{\ell’(\theta)}{\ell’'(\theta)}
$$
最后,在我们的逻辑回归设定中,$\theta$ 是向量值的,因此我们需要将牛顿法推广到这种设定下。牛顿法在多维设定下的推广(也称为 Newton-Raphson 方法)由下式给出:
$$
\theta := \theta - H^{-1} \nabla_\theta \ell(\theta)
$$
这里,$\nabla_\theta \ell(\theta)$ 是一如既往的 $\ell(\theta)$ 对 $\theta_i$ 的偏导数向量;而 $H$ 是一个 $d \times d$ 的矩阵(实际上,如果包含截距项,则是 $(d+1) \times (d+1)$),称为 海森矩阵(Hessian),其元素由下式给出:
$$
H_{ij} = \frac{\partial^2 \ell(\theta)}{\partial \theta_i \partial \theta_j}
$$
牛顿法通常比(批量)梯度下降具有 更快的收敛速度 ,并且只需要极少的迭代次数就能非常接近最小值。
然而,牛顿法的一次迭代可能比梯度下降的一次迭代更昂贵,因为它需要计算并求逆一个 $d \times d$ 的海森矩阵;但只要特征维度 $d$ 不是太大,它通常总体上要快得多。当牛顿法被用于极大化逻辑回归的对数似然函数 $\ell(\theta)$ 时,得到的方法也被称为 Fisher 得分法(Fisher scoring) 。