
物理存储结构与索引
存储与文件结构
文件组织
定长记录与变长记录
- 定长记录(fixed-length record):每条记录的长度相同,便于计算和存取
- 变长记录(variable-length record):每条记录的长度不同,节省空间,但存取较复杂
文件中记录的组织
堆文件组织(heap file organization)
记录无特定顺序存储,适用于插入频繁但查询较少的场景
顺序文件组织(sequential file organization)
记录按某一属性排序存储,适用于范围查询和顺序访问
散列文件组织(hashed file organization)
记录通过哈希函数映射到存储位置,适用于等值查询
多表聚簇文件组织 (clustered file organization)
将相关表的数据存储在一起,提高联接查询效率
数据字典 (Data Dictionary / System Catalog)
它是“数据库的数据库”。
存什么? 元数据 (Metadata)。即关于数据的数据。
- 表名、列名、列的类型。
- 完整性约束(主键、外键)。
- 用户权限信息。
- 统计信息(表有多少行?索引树有多高?——优化器用这些信息来决定怎么查询)。
怎么存? 通常,数据字典自己也是以“表”的形式存储的。比如 sys_tables, sys_columns。
缓冲区管理 (Buffer Management)
数据库不仅管磁盘,还要管内存。
Data Buffer (数据缓冲区): 磁盘太慢,内存太快。数据库必须在内存中开辟一块区域(Buffer Pool)来缓存从磁盘读上来的数据块(Block/Page)。
Buffer-Replacement Policies (置换策略): 内存满了,又有新数据要读进来,踢掉谁?
-
LRU (Least Recently Used): 踢掉最久没被访问的块。(操作系统常用,但数据库不一定好用)。
-
MRU (Most Recently Used): 数据库特有策略。
场景: 全表扫描。你读了第 1 页,处理完,读第 2 页… 第 1 页虽然刚用过,但大概率很久不会再用了。这时候 MRU(踢掉刚才读的)比 LRU(保留刚才读的)更好。 -
Pinned Blocks (钉住的块): 如果一个块正在被某个事务修改,或者正在写回磁盘的过程中,它被“钉住”了,绝对不能被踢走。
索引的基本概念
索引是数据库中用于加速数据检索的一种数据结构。它类似于书籍的目录,(search-key可类比为章节的名字,pointer可类比为页码)可以帮助数据库管理系统快速定位到所需的数据行,而无需扫描整个表。
物理存储在index file中,(search-key,pointer)
有两种基本的索引类型:
- 顺序索引(ordered Index)按照search-key排列,
- 哈希索引(Hash Index)
索引评价标准:
- 访问类型:支持等值查询 or 范围查询
- 执行时间:提高查询效率
- 插入时间:索引可能会增加数据增删的开销
- 删除时间
- 磁盘额外开销
顺序索引
索引文件中的记录是按照search-key排序的
聚集索引 vs 非聚集索引
- 主索引(primary index):索引文件顺序和数据文件一致,又叫做聚集索引(clustering index)一般是建立在主键上,但是不一定必须是主键,只能建一个主索引
- 辅助索引(secondary index)数据文件和索引顺序不一致,他一定是稠密的,对等值有效,对范围查询效果不好,也叫做非聚集索引(unclustering index),可以建立多个辅助索引
稠密索引 vs 稀疏索引
- 稠密索引dense index :数据文件的每一条记录在索引文件中都有对应的索引项,在稠密聚集索引中,记录包含search-key和指向数据第一条记录的指针。在稠密非聚集索引中,索引项包含search-key和指向所有数据记录的指针。
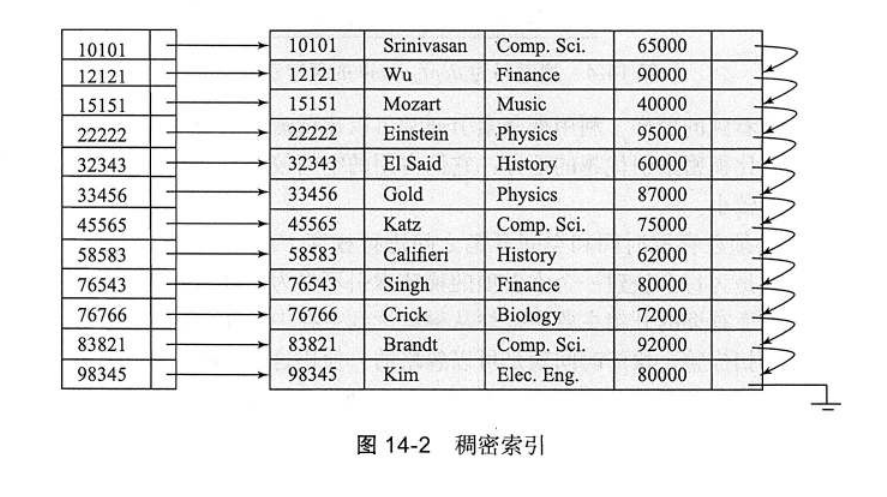
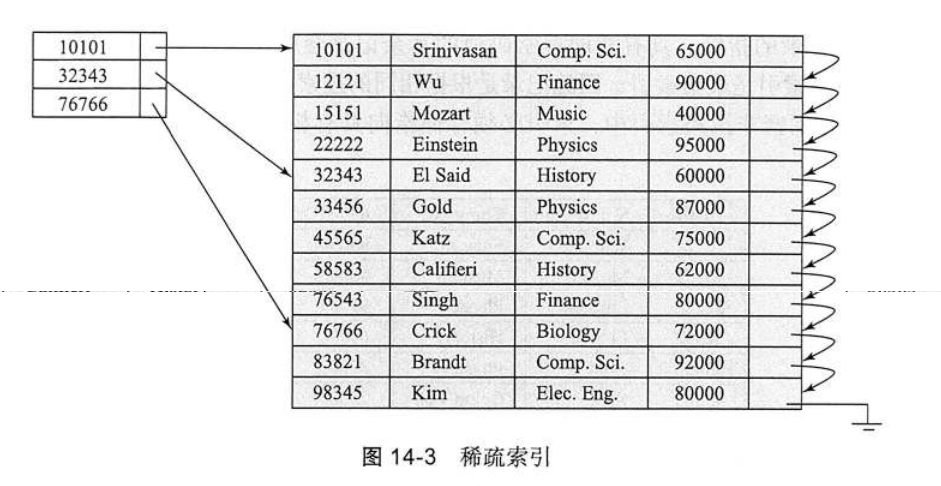
- 稀疏索引sparse index:只为某些搜索码建立索引项,只有索引是聚集索引时,才能使用稀疏索引,因为稀疏索引只能用于顺序存储的数据文件。如下图,若要搜索编号为22222的记录在索引表中是找不到的,只能找到10101,然后顺序查找数据文件。如果数据文件是无序存储的,就无法使用稀疏索引了。
多级索引
多级索引(multilevel index)在索引之上建索引。若索引太多,索引块太大,为了尽快找到这个索引,就为索引建立索引,
哈希索引
SQL索引语句
create unique/noncluster/cluster index 索引名 on 表名(属性名)
drop index 索引名
索引建立原则
where
group by
后面出现的属性可建立索引