
数据库设计
数据库设计
概念模式设计
E-R模型
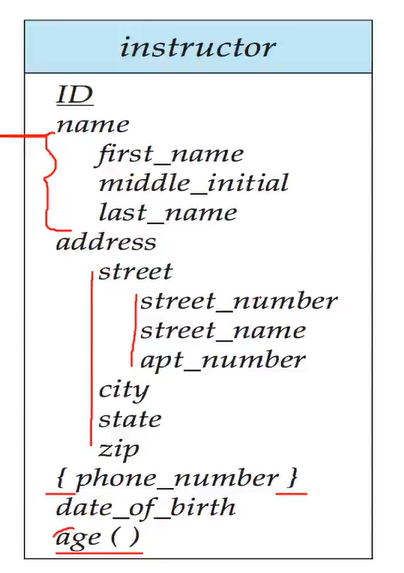
实体集 entity sets
具有相同属性attributes的实体构成一个实体集。实体指一个具体的个体,如一个特殊的人,一个公司,一件事。
下图为实体集的E-R图
属性 attributes
- 简单属性(Simple):不可再分的属性
- 复合属性(composite):可在分的属性 用缩进表示
根据用户需求来确定属性是简单的还是复杂的。比如姓名这个属性,根据用户需求可看成一整个名字的简单属性,也可以看成姓和名的复合属性。
- 单值属性(Single-valued):在这个属性上的取值只有一个。比如性别,要么是男,要么是女,不可能同时是男和女。
- 多值属性(multivalued):比如联系方式,可以填多个电话或邮箱 用{}表示
- 导出属性(Derived):可以由其他属性推导出来。比如年龄可以根据生日算出。导出属性可以在数据库中存也可以不存,存的话得到属性比较快,但是,不仅占空间,而且需要维护它和其他属性的一致性。所以对于一些简单的逻辑关系,就不保存了。 用()表示
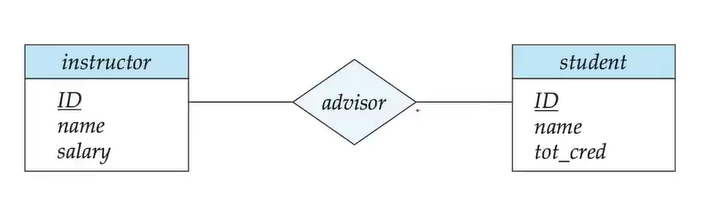
联系集 relationship sets
实体集之间存在的某种语义关系。
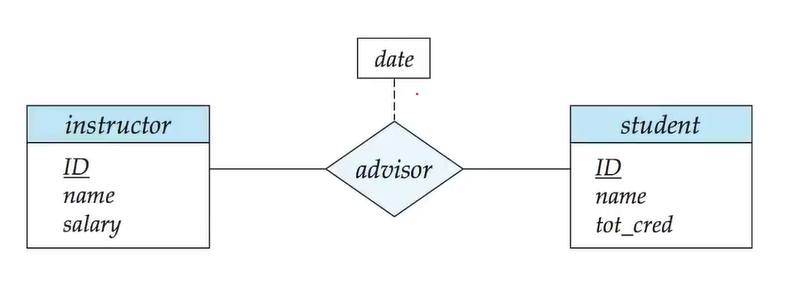
联系集也可能有属性。比如,老师开始指导学生的开始时间,这个时间既不是老师的,又不是学生的,是联系集的。
再换一种说法,一个订单要购买几种产品,那么这几种产品的数量是订单的属性吗?是产品的属性吗?都不是,是下单这个关系的属性
张三的数据库成绩是90分,而不是张三的成绩是90分,数据库的成绩是90分,而是这个选课关系上的属性
联系集用菱形框表示
虚线上的表示联系集的属性
联系集的度(drgree) :联系实体集的个数
相同的实体集可以产生不同的联系,所以E-R图要标出来联系的名字
映射基数 Mapping Cardinality Constraints :在数据库设计和关系映射中用于定义实体之间关系的约束。描述了两个实体之间的关系可以有多少个实例。
- 一对一:A一个实体只能与B至多一个实体相关联
- eg:男人集和女人集,联系为夫妻,一个丈夫只有一个妻子,一个妻子只有一个丈夫。
- 一对多:A一个实体可以与任意数量的B实体关联
- eg: 班级和学生,联系为从属,一个班级可有多个学生,一个学生只属于一个班级
- 多对一:B一个实体可以与任意数量A实体关联
- 多对多:A一个实体可以与任意数量的B实体关联, B一个实体可以与任意数量的A实体关联
- eg: 老师和学生,联系为师生,一个老师可以教多个学生,一个学生可有多个老师
- 用 $\rightarrow$表示一
- 用
——表示多
一个老师能指导多个学生,但一个学生只能一个老师指导
弱实体集 weak entity sets
实体集没有主键。如在企业员工管理系统中,要存家属的信息,我们只关心家属姓名,年龄,与该员工的关系。只需要关注这三个属性,但这三个属性有可能有重复,所以家属的实体集就是弱实体集。弱实体集必定依赖于一个强实体集(标识实体集),比如员工集。
弱实体集部分键与强实体集一些属性确定一个特定的弱实体,下方有虚下划线
弱实体集用双矩形框表示
角色 roles
表示一元联系,course_id和prereq_id这样的标签就是角色
全参与和部分参与
用单线表示部分参与,用双线表示全参与
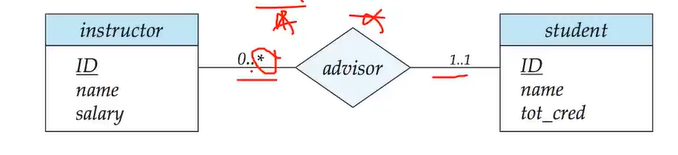
有些老师不指导学生,但学生肯定有老师
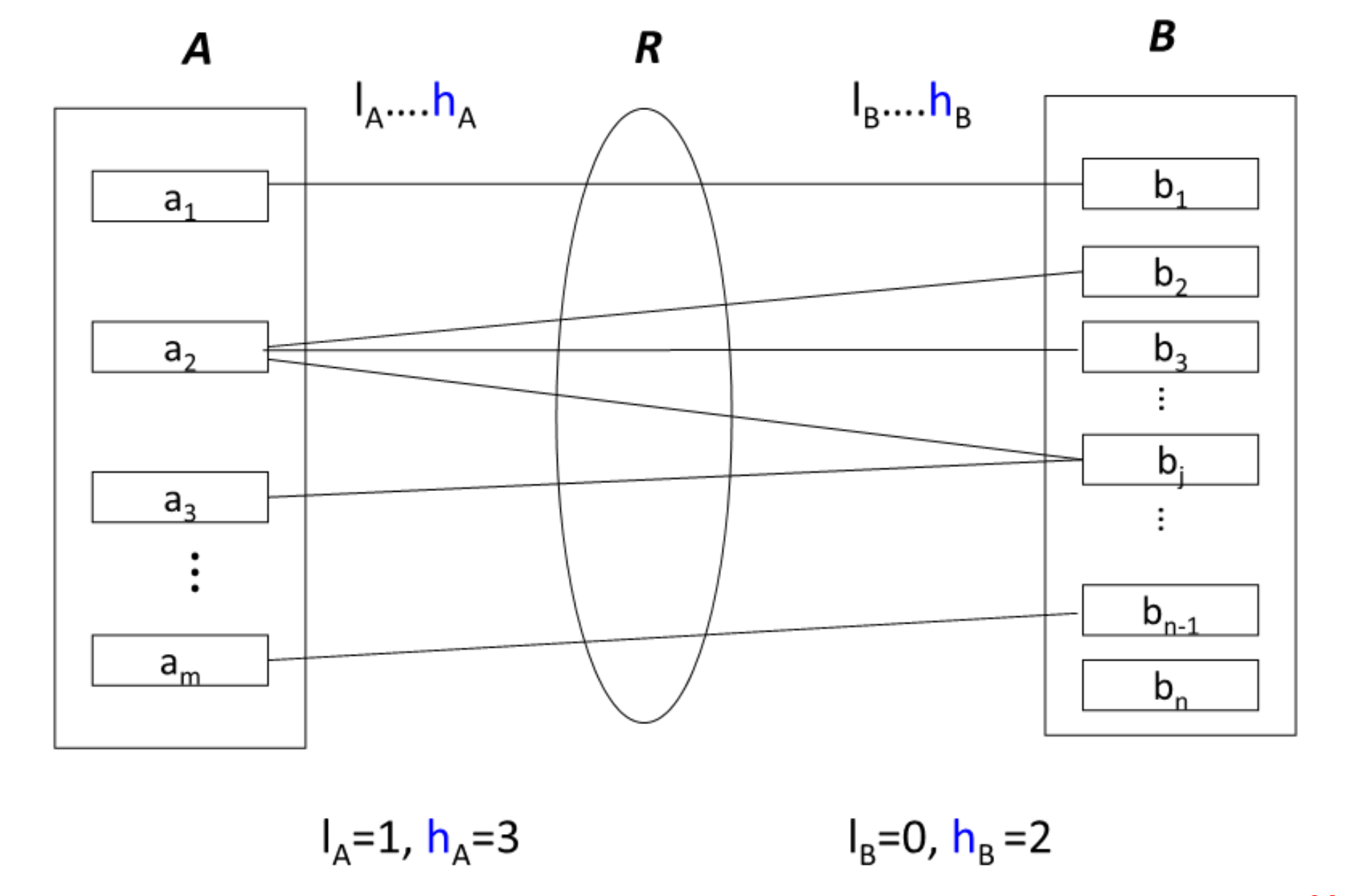
(l,h)
l表示全参与还是部分参与,>=1时表示全参与,=0时表示部分参与
h表示一对多还是多对多,一对一,‘*’/N表示多,1表示至多一个实体参与联系集
这个图中(0,*)表示部分教师参与指导学生,一名教师可以有不定量学生
(1,1)表示每个学生都要有老师,且至多只有一个老师指导
三元关系上的基数约束 ternary relationship cardinality
核心规则:一个三元或更高的关系,最多只能有一个箭头指出去,用来表示基数约束。
假设我们有一个三元关系,叫做学生选课 ,它连接了三个实体:
- 学生 (Student)
- 课程 (Course)
- 教授 (Professor)
这个“学生选课”关系(菱形)就表示:某个学生选了某个教授开的某门课程。
我们只画 1个箭头,比如从“学生选课”这个关系指向 教授。这代表什么?含义是:
- 剩下的两个实体(学生 和 课程)的组合,最多只能对应一个教授。
- 说人话就是: 对于一个特定的学生(比如你)和一门特定的课程(比如“数据库”),你最多只能有一个教授。
- 这很合理: 你选“数据库”这门课,要么是张三教授教,要么是李四教授教,你不能同时有两个教授给你上这同一门课。
- 用公式表达就是: (学生, 课程) $\rightarrow$ 教授。这个含义是非常清晰、没有歧义的。
现在我们来看看如果我们画了多个箭头会发生什么:
假设我们在“学生选课”关系上画了两个箭头:一个指向 教授,另一个指向 课程。这就意味着:
歧义 1 (PPT 里的第 1 种解释):
是不是指“学生”是核心?
意思是:“每一个学生,最多只能关联一个教授(一辈子只能有一个教授?),并且 最多只能关联一个课程(一辈子只能选一门课?)”
这个解释显然很荒谬,但它是一种可能的“语法”解释。
歧义 2 (PPT 里的第 2 种解释):是不是指两个独立的规则?规则 A (来自指向教授的箭头): (学生, 课程) $\rightarrow$ 教授。(你选的数据库课,只有一个教授)。规则 B (来自指向课程的箭头): (学生, 教授) $\rightarrow$ 课程。(你选了张三教授,那么你只能上他开的一门课吗?比如你不能同时选张三教授的“数据库”和“操作系统”?)。
特化 specialization 与 概化 generalization
正交与重叠
- 正交:一个教师只能是教授或讲师中的一个,这叫做不重叠/正交(disjointness)
- 重叠:一个官员可以同时是省委常委和市委书记,这叫做重叠(overlapping)
完全和部分
- 完全:子类完整地覆盖父类所有的情况,没有遗漏,且每个父实体集的实例都必须属于某个子实体集。
- 部分:子实体集的属性不完全包含在父实体集中,且父实体集的实例可以不属于任何子实体集。
所以有四种组合:
- 正交完全特化/概化
- 重叠完全特化/概化
- 正交部分特化/概化
- 重叠部分特化/概化
特化是一种自顶向下的过程,从一个较大的实体集派生出更小的实体集。
概化是一种自底向上的过程,将多个较小的实体集合并成一个较大的实体集。
特化和概化只是一种思想,E-R图中只表示最后设计的结果,不表示设计的过程。
聚集 aggregation
步骤 1:一个基本关系
首先,我们有两个实体:
- 学生 (Student)
- 项目 (Project)
它们之间有一个多对多(M:N)的关系: - 参与 (Participates_In)
一个学生可以参与多个项目,一个项目可以有多个学生参与。
[学生] $\longleftrightarrow$ (参与) $\longleftrightarrow$ [项目]
步骤 2:出现的问题
现在,我们想引入一个新的实体:
- 教授 (Professor)
教授的职责是“评审”(Evaluates)某个学生在某个项目上的工作。
问题来了:这个“评审”关系,应该连接谁? - 连接 教授 和 学生?不行。教授不是评审一个“学生”(这个人),而是评审他在某个项目上的工作。
- 连接 教授 和 项目?不行。教授不是评审一个“项目”(比如项目经费),而是评审某个学生在该项目上的工作。
- 这个 评审 关系,它真正要连接的对象是:教授 和 “学生参与项目”这件事情本身。
但是“学生参与项目”是一个关系 (参与),而不是一个实体。我们不能直接把 教授 实体连接到 参与 这个菱形上。
步骤 3:使用“聚集”解决“聚集”允许我们这样做:
- 我们先把 [学生] $\longleftrightarrow$ (参与)$\longleftrightarrow$ [项目] 这个整体结构,用一个大的虚线框给“打包”起来。
- 这个“大虚线框”现在就被视作一个单一的、抽象的实体。我们可以给它起个名字,比如叫 项目工作 (Project_Work)。
- 这个 项目工作 实体,就代表了“一个学生参与一个项目”的具体实例。
- 现在,我们就可以创建一个新的关系,比如叫 评审 (Evaluates),来连接 [教授] 实体和这个新的 [项目工作](大虚线框)了。
1 | + - - - - - - - - - - - - - - - + |
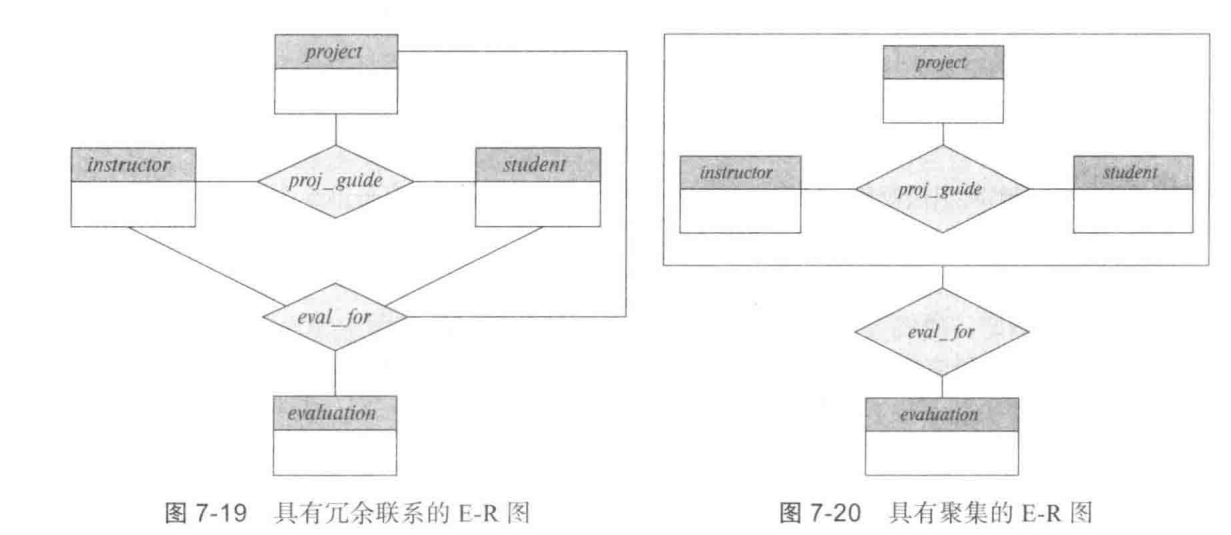
上图解释了如何使用聚集解决联系中的联系
E-R图转关系模型
一对一:在任意一方加入另一方主键和关系属性
一对多:在多的那一方加入一的那方的主键和关系属性
多对多:将联系单独作为一个关系模型,加入双方主键
弱实体集:将强实体集的主键加入自己
多值属性:将主键和该属性单独作为一个关系模型,两个主键
分段属性:按分段的来填入属性
关系数据库设计
不良模式分析
数据冗余,插入异常,删除异常,更新异常
函数依赖
一个属性集X函数依赖于另一个属性集Y,记为X $\rightarrow$ Y,表示在关系R中,如果两个元组在X上的值相同,那么它们在Y上的值也必须相同。

函数依赖分为以下几类:
平凡依赖 trivial functional dependency
$\alpha \rightarrow \beta$ is trivial if $\beta \subseteq \alpha$
姓名确定姓名
姓名加性别确定姓名
传递依赖
$\alpha \rightarrow \beta$ and $\beta \nrightarrow \alpha$ and $\beta \rightarrow \gamma$ then $\alpha \rightarrow \gamma$
课程编号函数确定老师编号,老师编号函数确定住址,那么课程编号确定住址
部分依赖
$\alpha \rightarrow \beta$ and $\gamma \subset \alpha$ and $\gamma \rightarrow \beta$ then $\alpha \rightarrow \beta$ is a partial dependency
逻辑蕴含
每个部分依赖都能推出来传递依赖
$\alpha \rightarrow \beta$ 是部分依赖,$\gamma \subset \alpha$ and $\gamma \rightarrow \beta$
$\alpha \rightarrow \gamma$
so $\alpha \rightarrow \beta$ 是传递依赖
函数依赖集闭包
从已知函数依赖,推导出全部的隐含函数依赖。
使用$F^+$表示函数依赖集的闭包。
$F^+$ = ${A->B,B->C}^+$ =
范式
第一范式 1NF
关系中的每个属性都是原子值,即不可再分的基本数据项。
例如,学生表中的“姓名”属性是原子值,而“地址”属性如果包含“省”、“市”、“区”三个部分,则不是原子值。
第二范式 2NF
满足1NF,并且每个非主属性完全依赖于主键,而不是部分依赖。
第三范式 3NF
满足2NF,并且不存在传递依赖。
博茨-科得范式 BCNF
满足3NF,并且对于每个非平凡函数依赖X->Y,X必须是超键。简单点说就是,关系中的每个决定因素都是候选键。
求候选键
- 找出L,R,LR,N
- X_set = $L\cup N$ Y_set = LR
- 若X_set中非空集,计算$X_set^+$,若涵盖所有,则X_set为候选键
- 若$X_set^+$不涵盖所有,则从Y_set中依次取一个属性加入X_set,计算闭包,
- 计算完成之后,若每个都可以则结束,否则继续从Y_set中取两个属性加入X_set,步骤4中已经算出来的候选键不参与计算,重复4过程
求最小覆盖
- 将每个函数依赖右边拆分成单属性 如 AB->DE 拆成 AB->D AB->E
- 消除冗余函数依赖 从左到右依次看如果删除这个函数依赖是否还能推出来这个关系 如 删除 AB->D 后能否AB还能否推出来D,能则删除,不能则保留
- 消除冗余函数依赖 像AB->D 看A能否推出来B,能则改成A->D,再看B能否推出来A,能则改成B->D
- 合并同意函数依赖 如 A->D A->E 合并成 A->DE
3NF分解算法
- 先计算F的最小覆盖G
- 计算G的候选键
- 将G中每个函数依赖X->Y转换为关系模式R(X $\cup$ Y)
- 若上一步中没有包含候选键,则添加一个关系模式R’,其属性为候选键,若有多个候选键,只用添加一个
BCNF分解算法
- 计算候选键
- 检查每个函数依赖X->Y,若X不是候选键,则违反BCNF
- 将关系模式R分解为R1和R2,R1的属性为X $\cup$ Y,R2的属性为R-R1+X
- 对R1和R2重复步骤2和3,直到所有关系模式都满足BCNF
判断范式类型
- 计算候选键
- 若存在X->Y,X是候选键的一部分,Y是非主属性,则为1NF,否则为2NF。两边都是非主属性不用考虑。
- 对于任意函数依赖 𝑋→𝐴,要么𝑋是超键,要么A 是主属性(属于某个候选键),则他是3NF
- 继续看是否每个函数依赖左边都是超键,是则为BCNF,否则为3NF